生成式AI导论
Categories: AI
本文为台大李宏毅【生成式AI導論 2024】课程笔记
1.什么是生成式人工智慧
1.1.概述
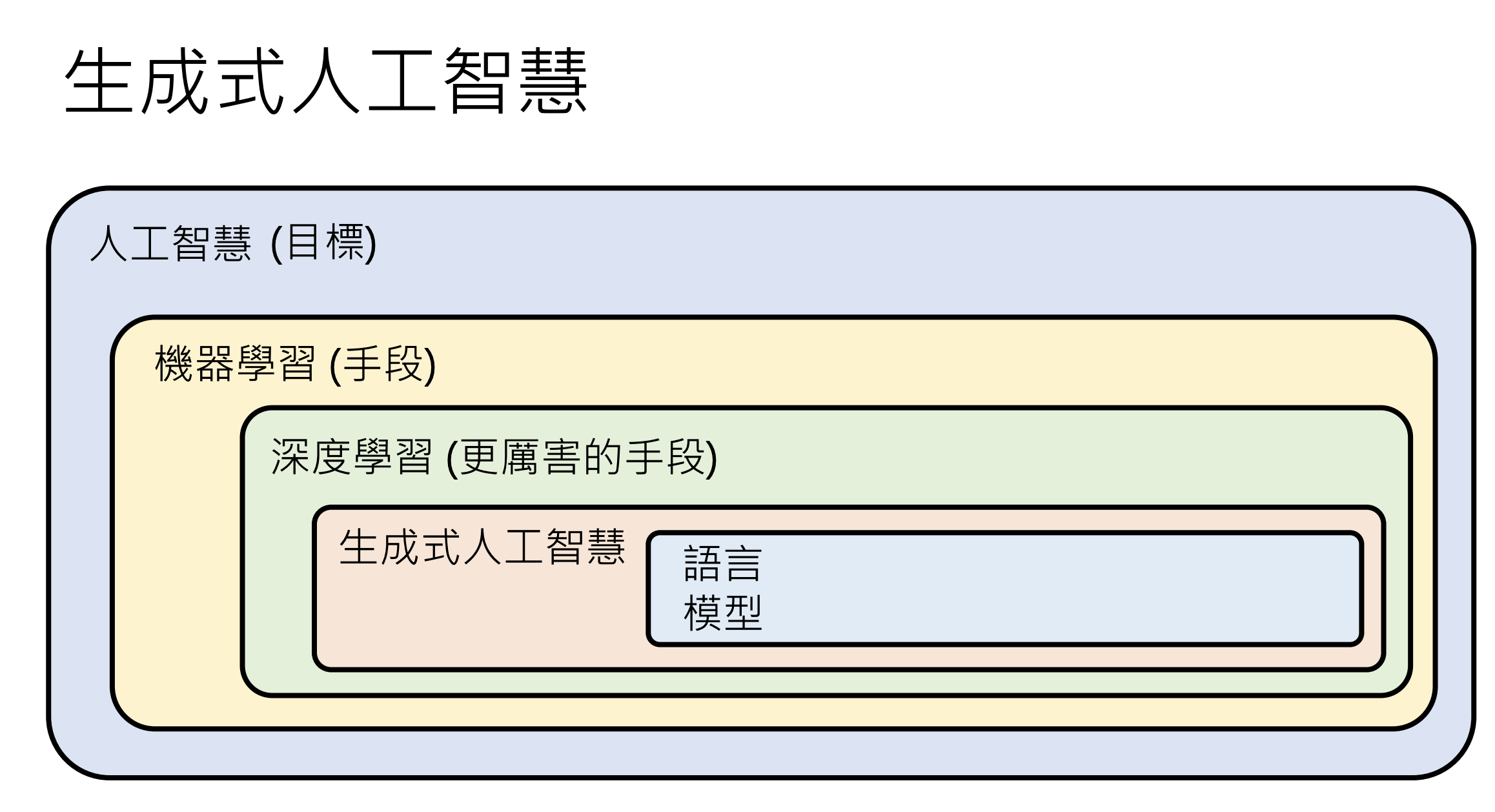
人工智慧 (Artificial Intelligence, AI):是一个目标,让机器展现「智慧」;
生成式人工智慧 (Generative AI):机器产生复杂有结构的物件(近乎无法穷举);
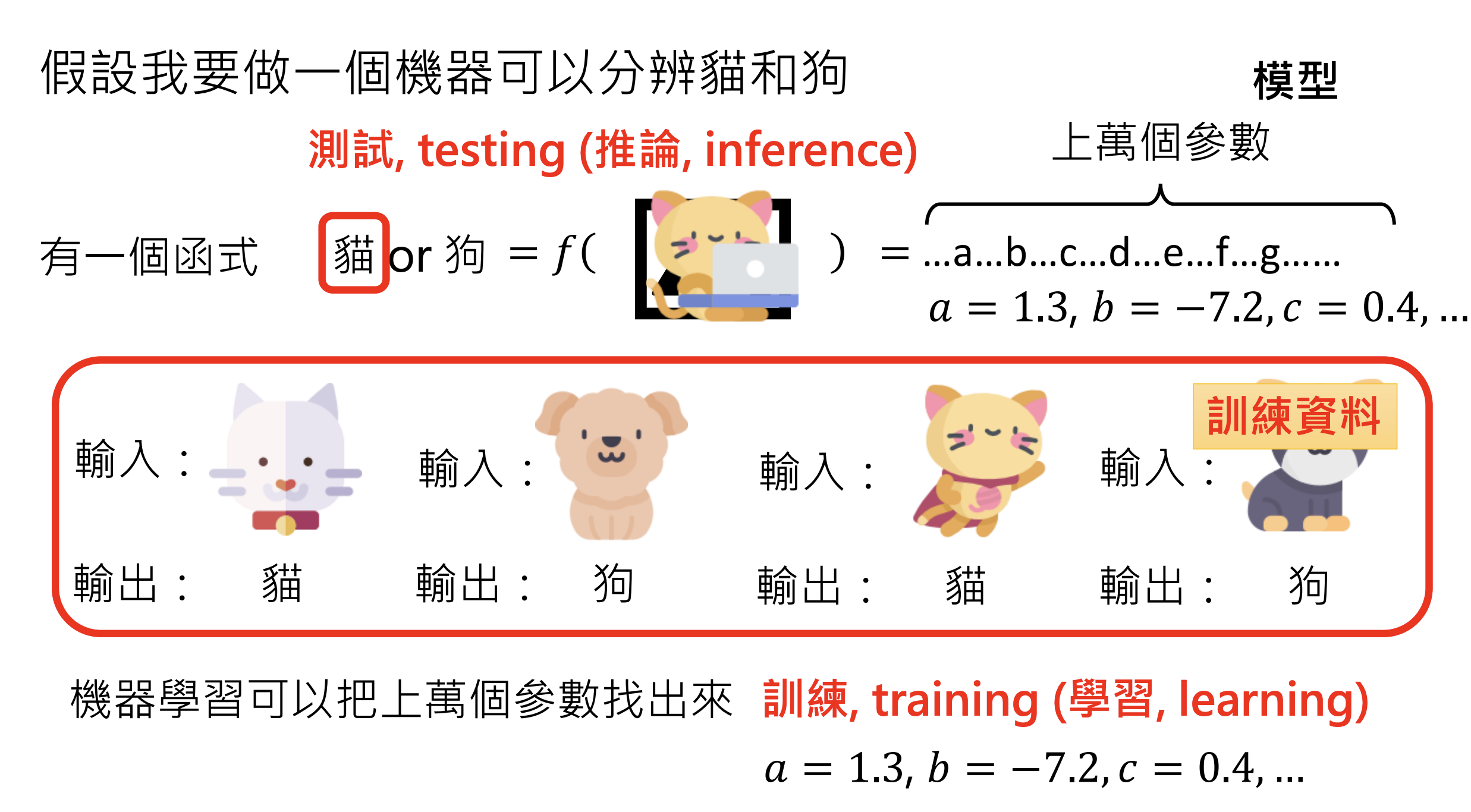
机器学习(Machine Learning):机器自动从资料找到一个函数;
机器学习案例:
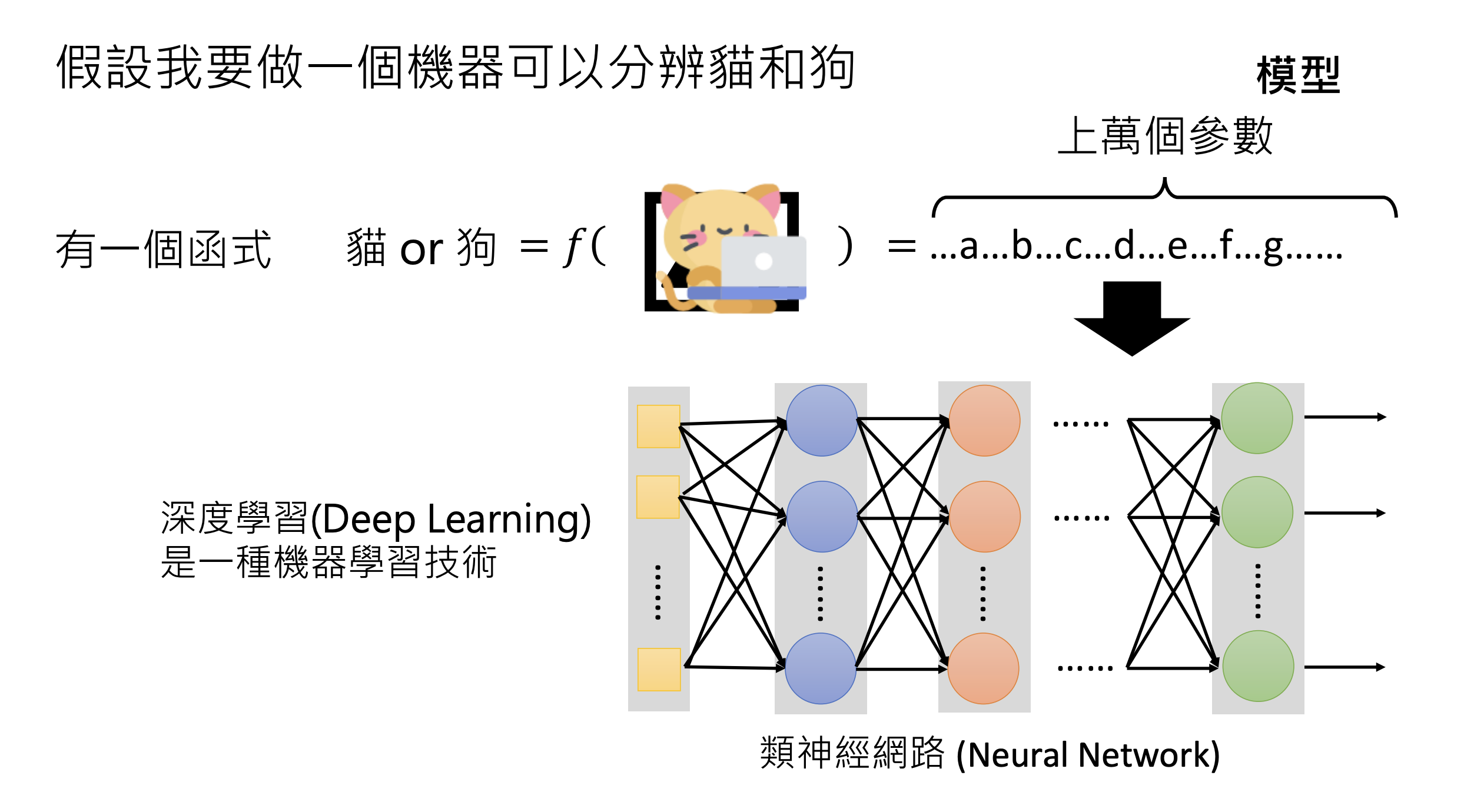
1.2.结构
1.3.应用
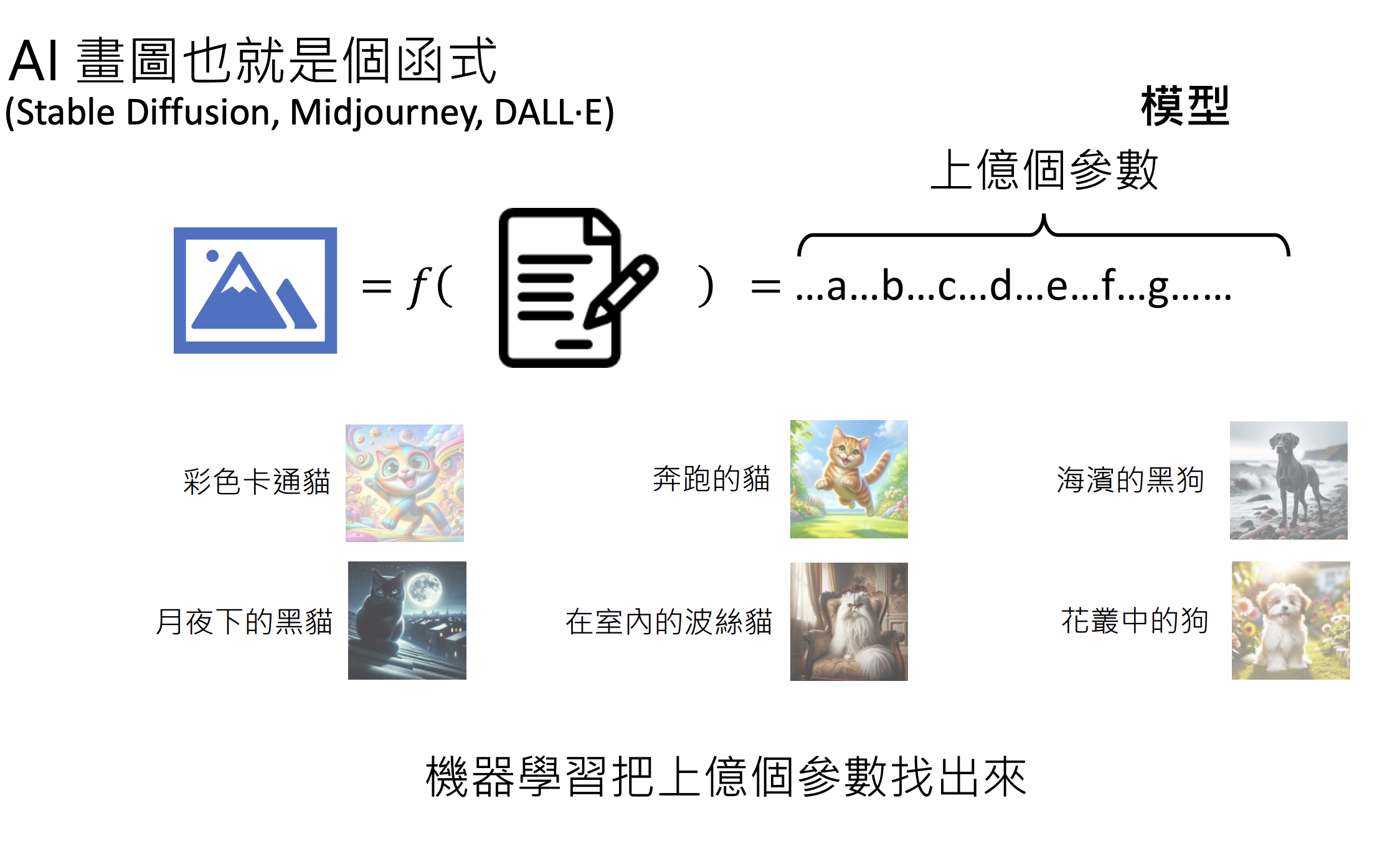
1.4.原理
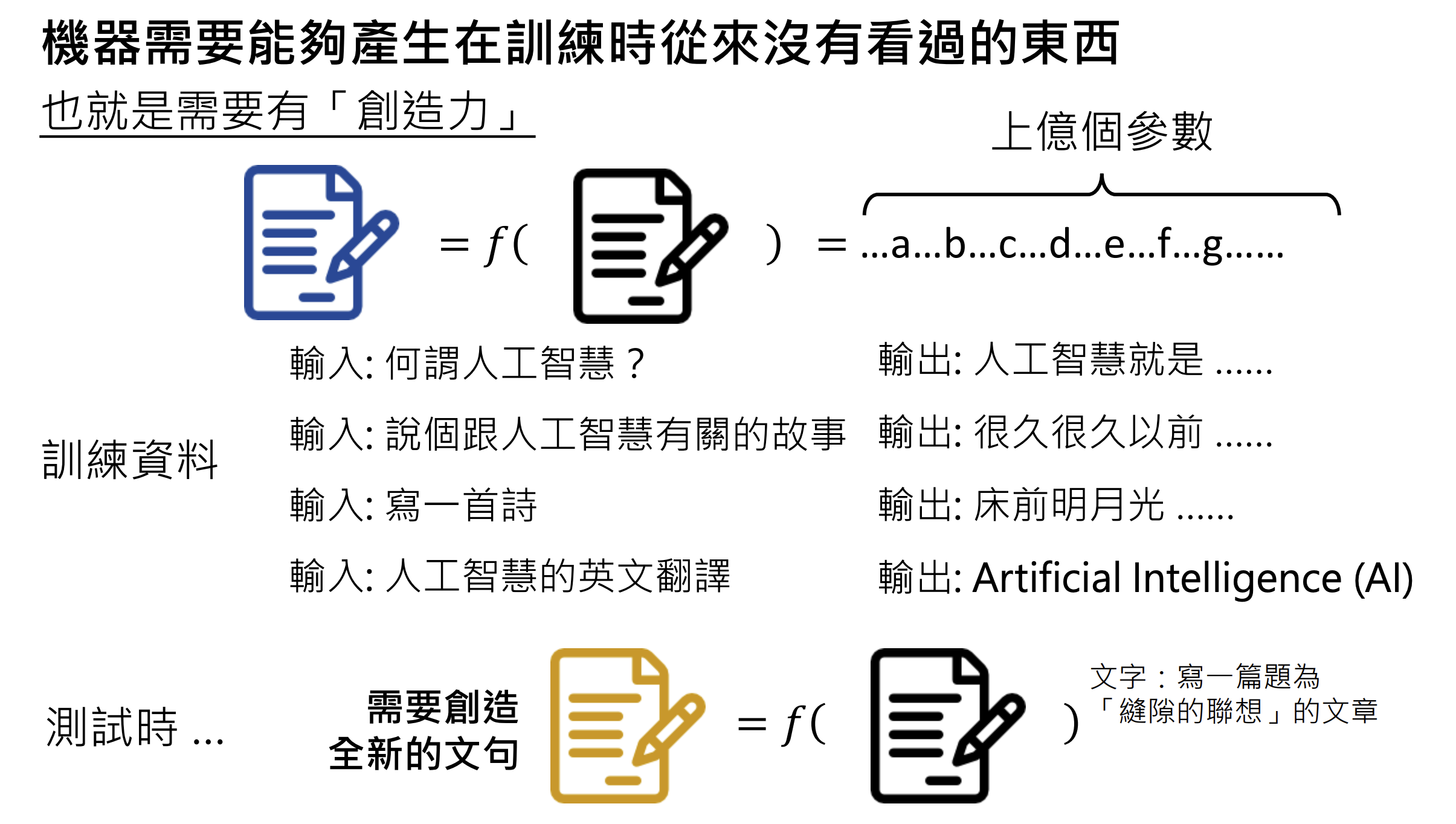

2.生成式人工智慧厉害在哪里?
2.1.概述
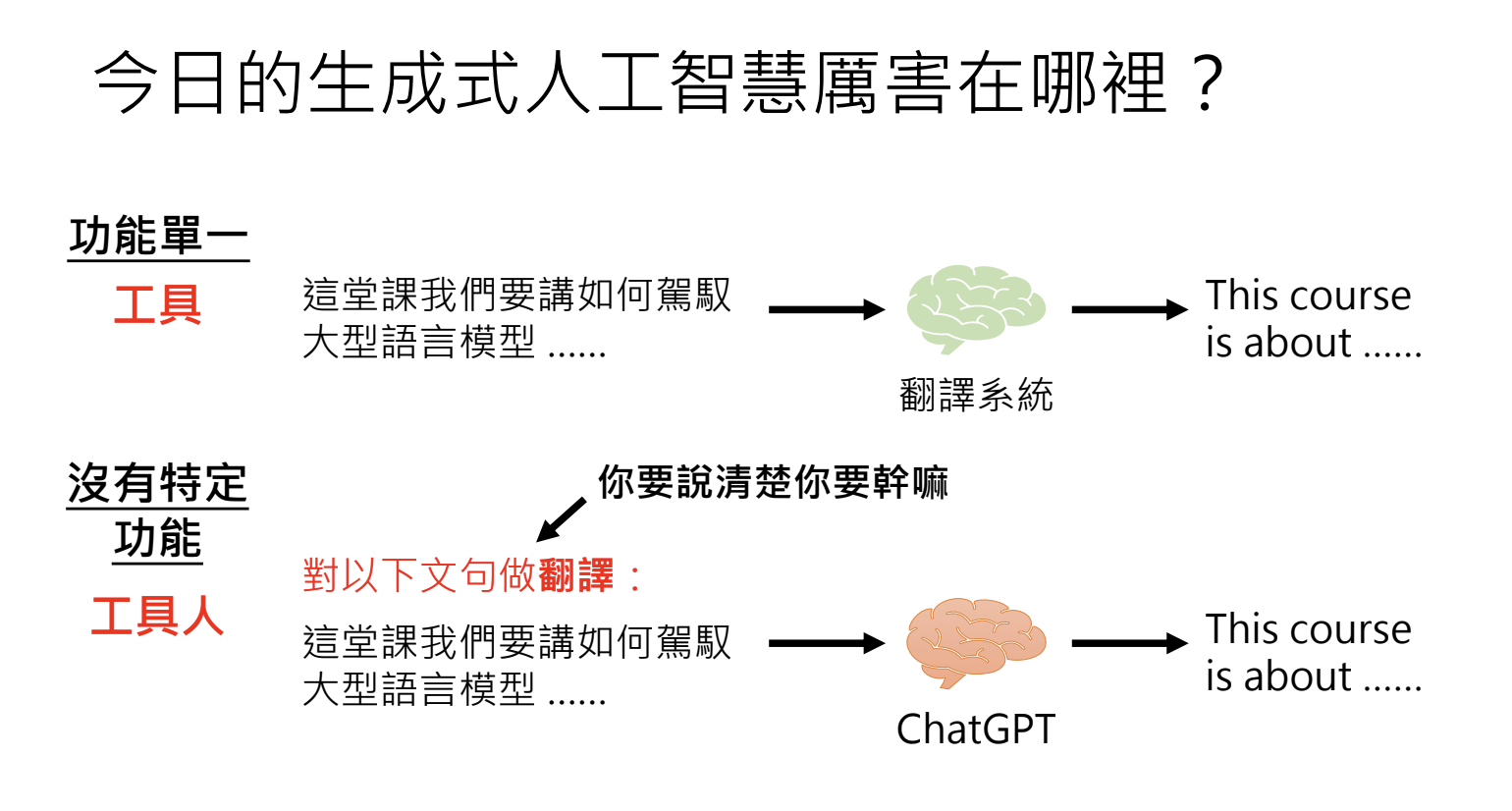
2.2.发展方向
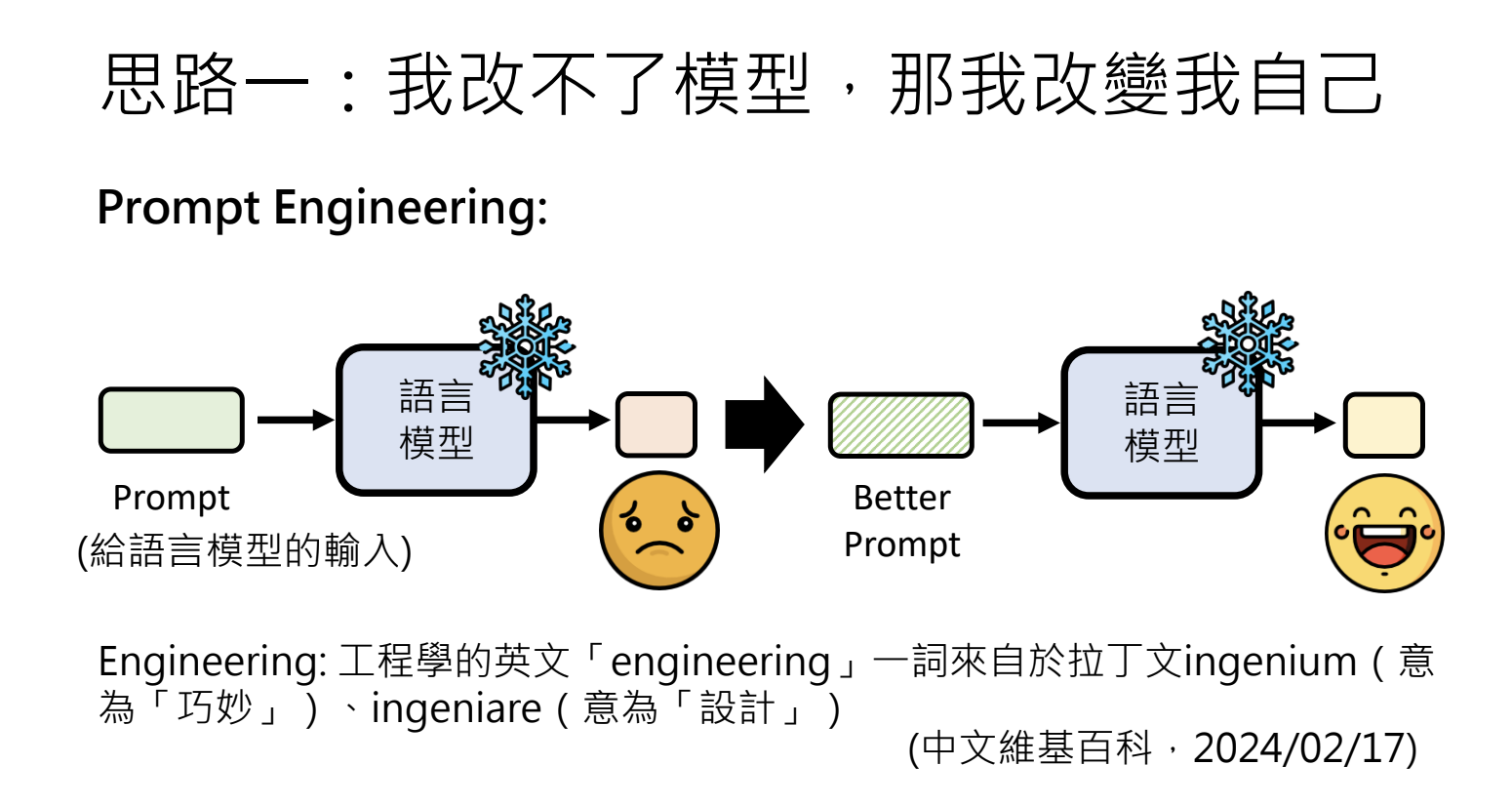
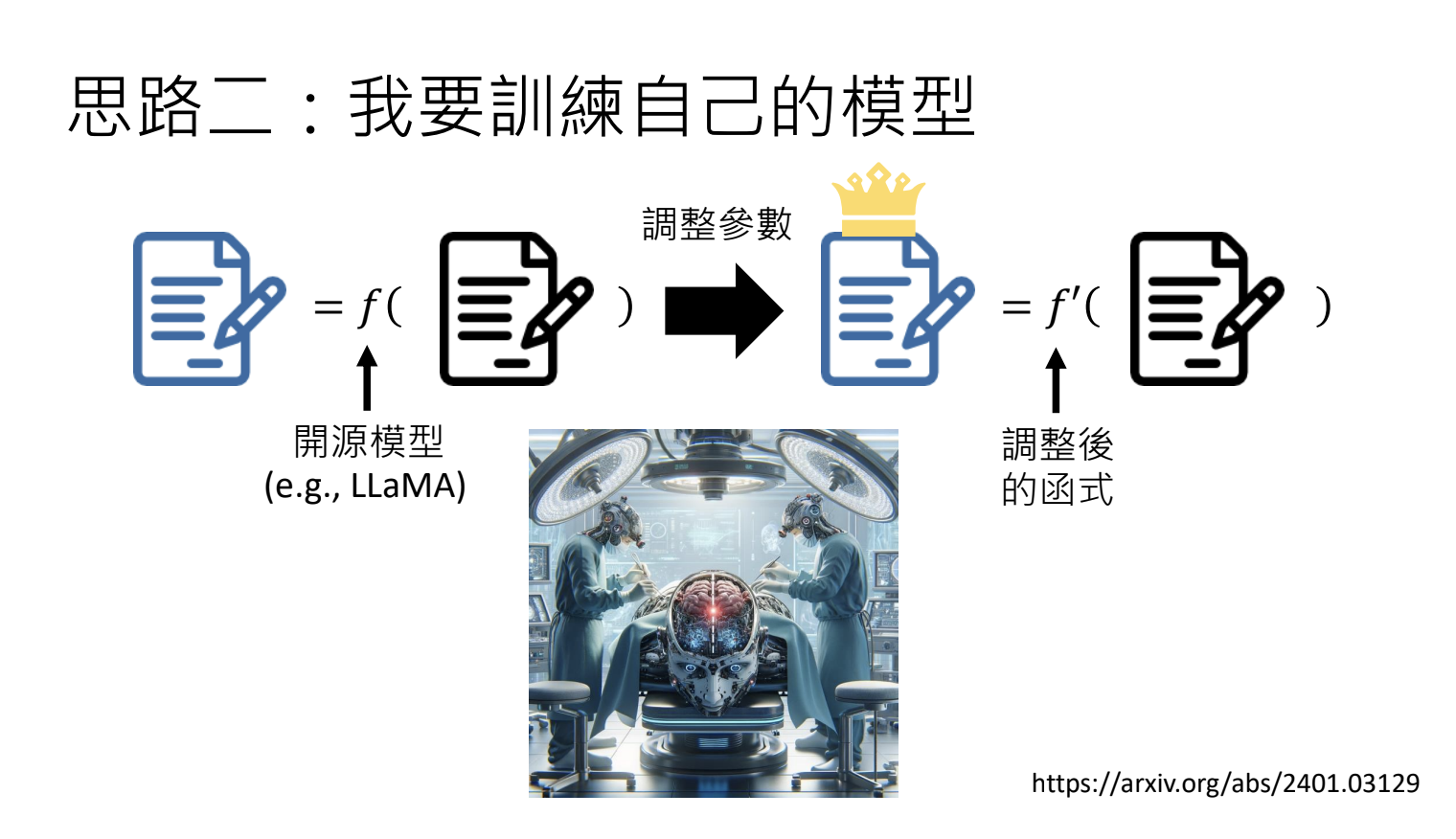
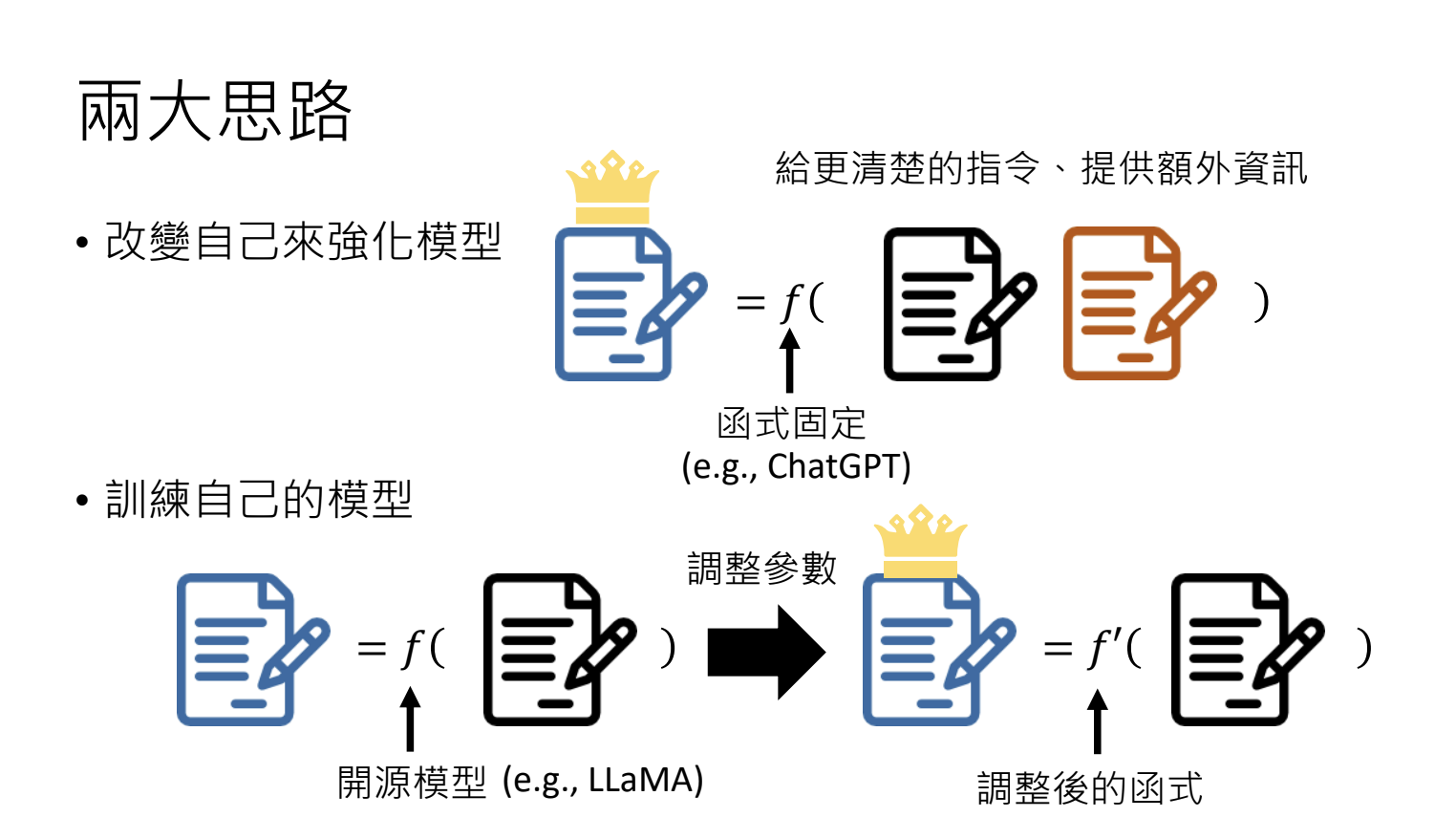
3.训练不了人工智慧?你可以训练你自己
3.1.模型合作
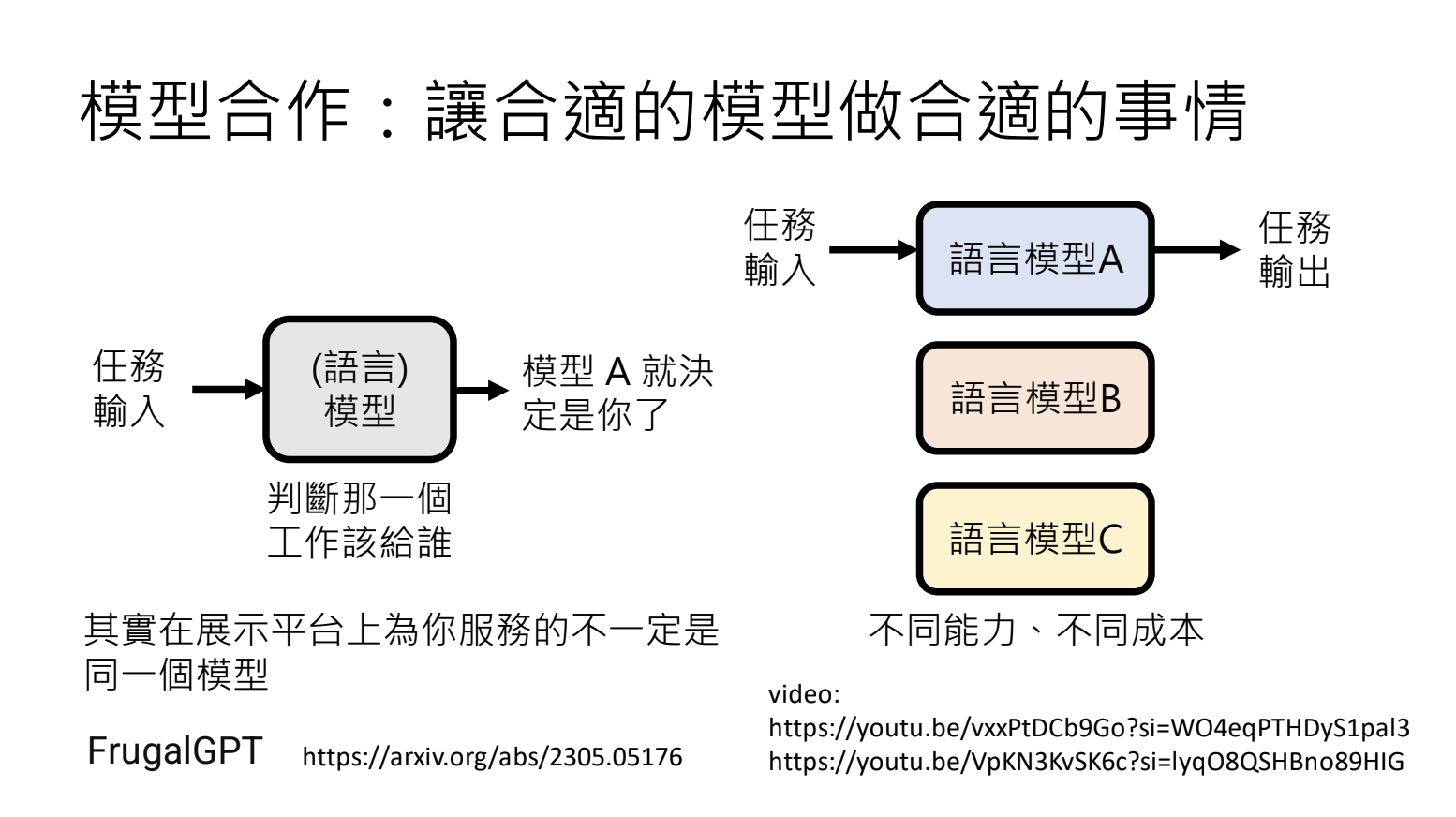
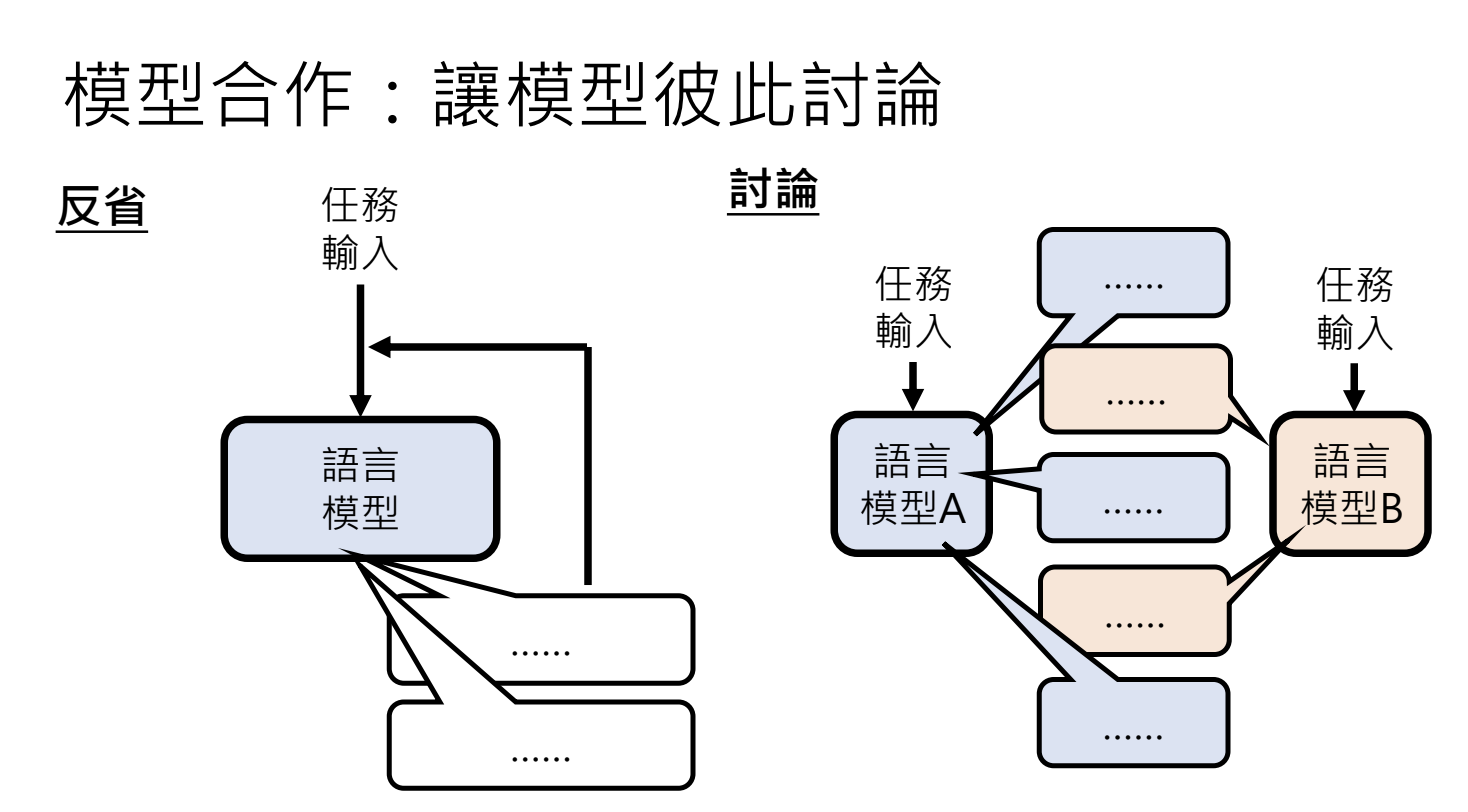
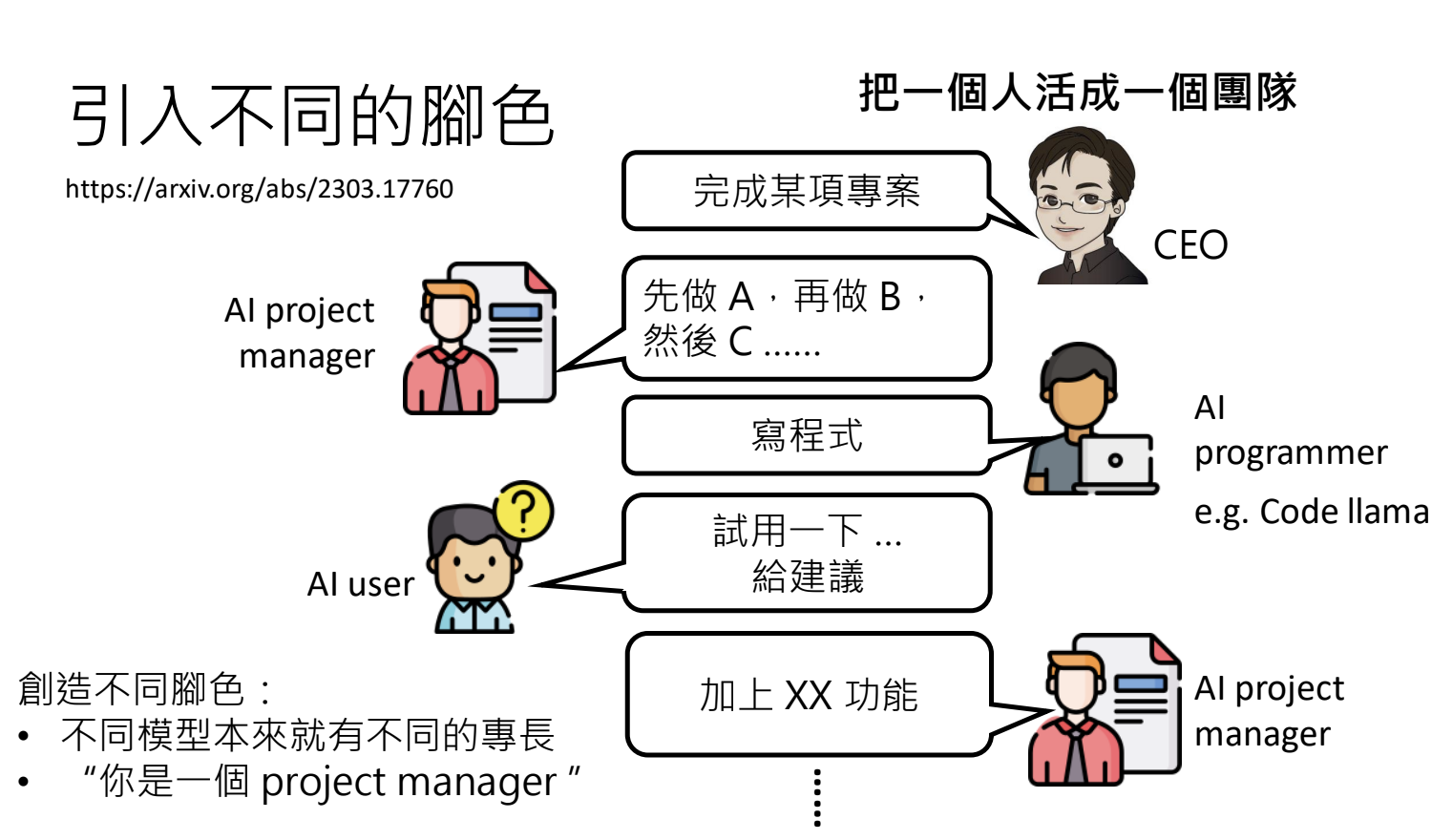
3.2.引入不同的角色

4.大型语言模型修炼史
4.1.基本概念
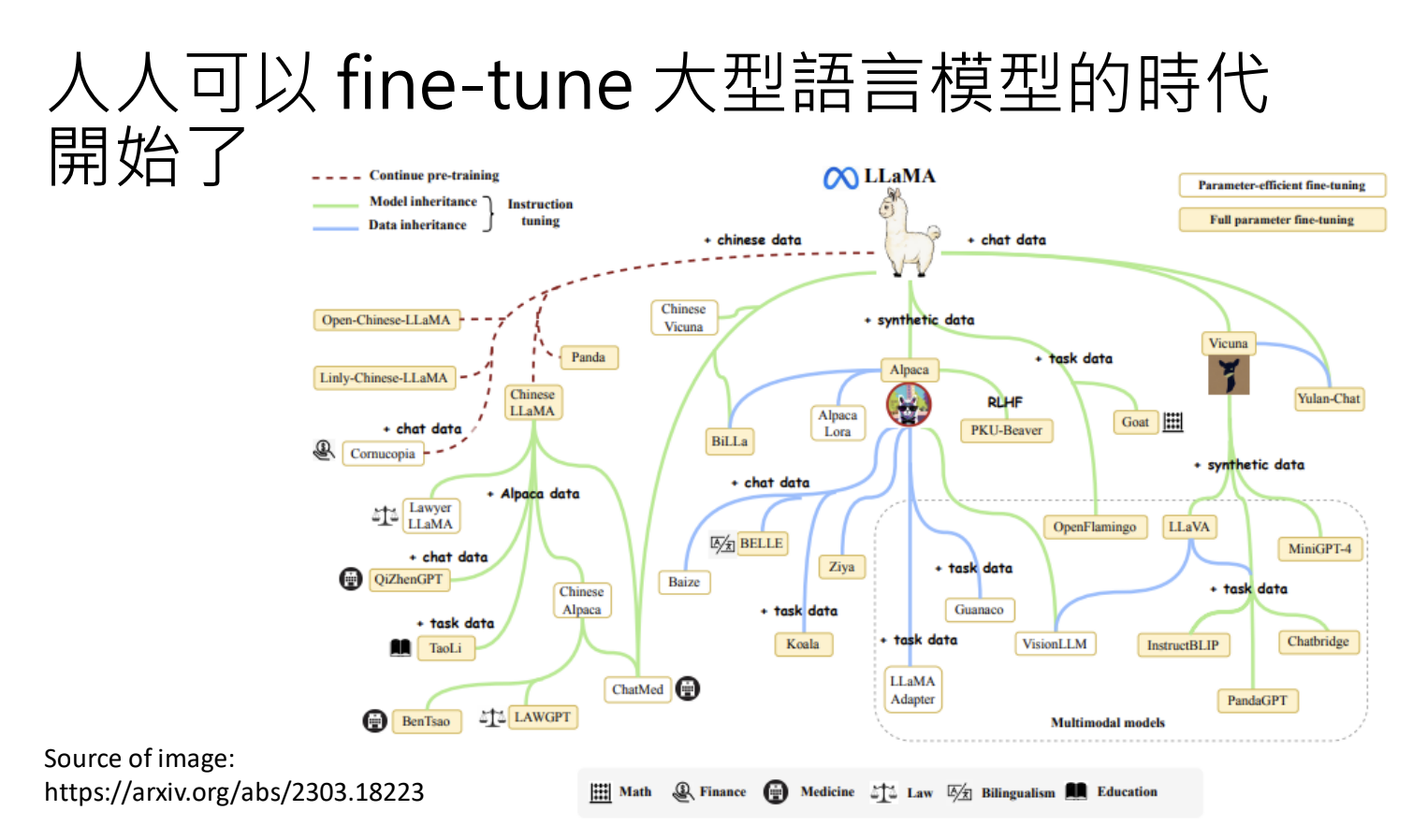
机器学习的目标是找出模型参数,使之符合训练资料。分为训练(Training)和推论(Inference)两阶段
- 训练:设定超参数,透过最佳化找出参数;
- 推论:使用已训练的参数进行推论;
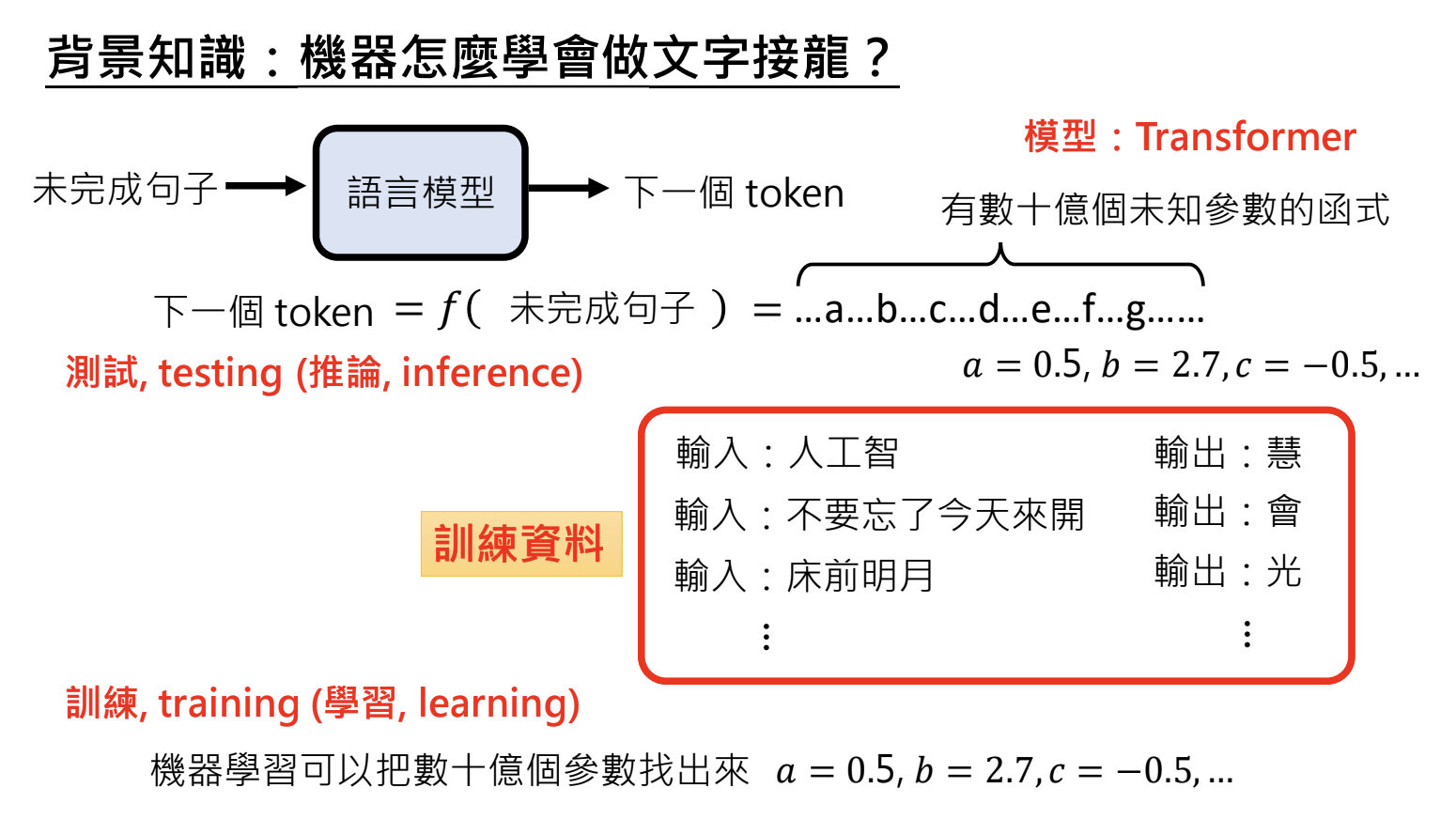
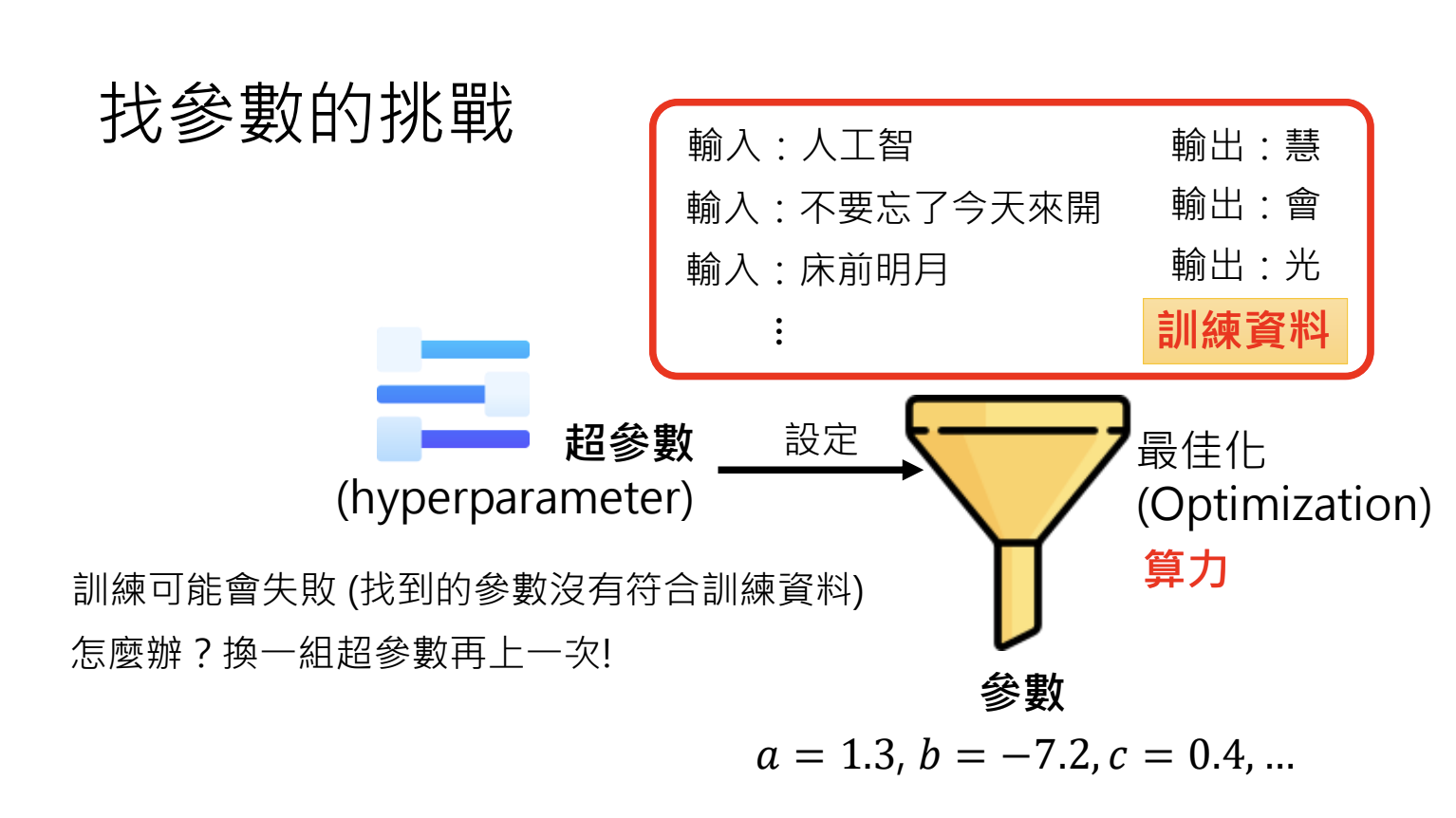
4.2.训练挑战
- 超参数设定:影响最佳化结果,需多次尝试调整;
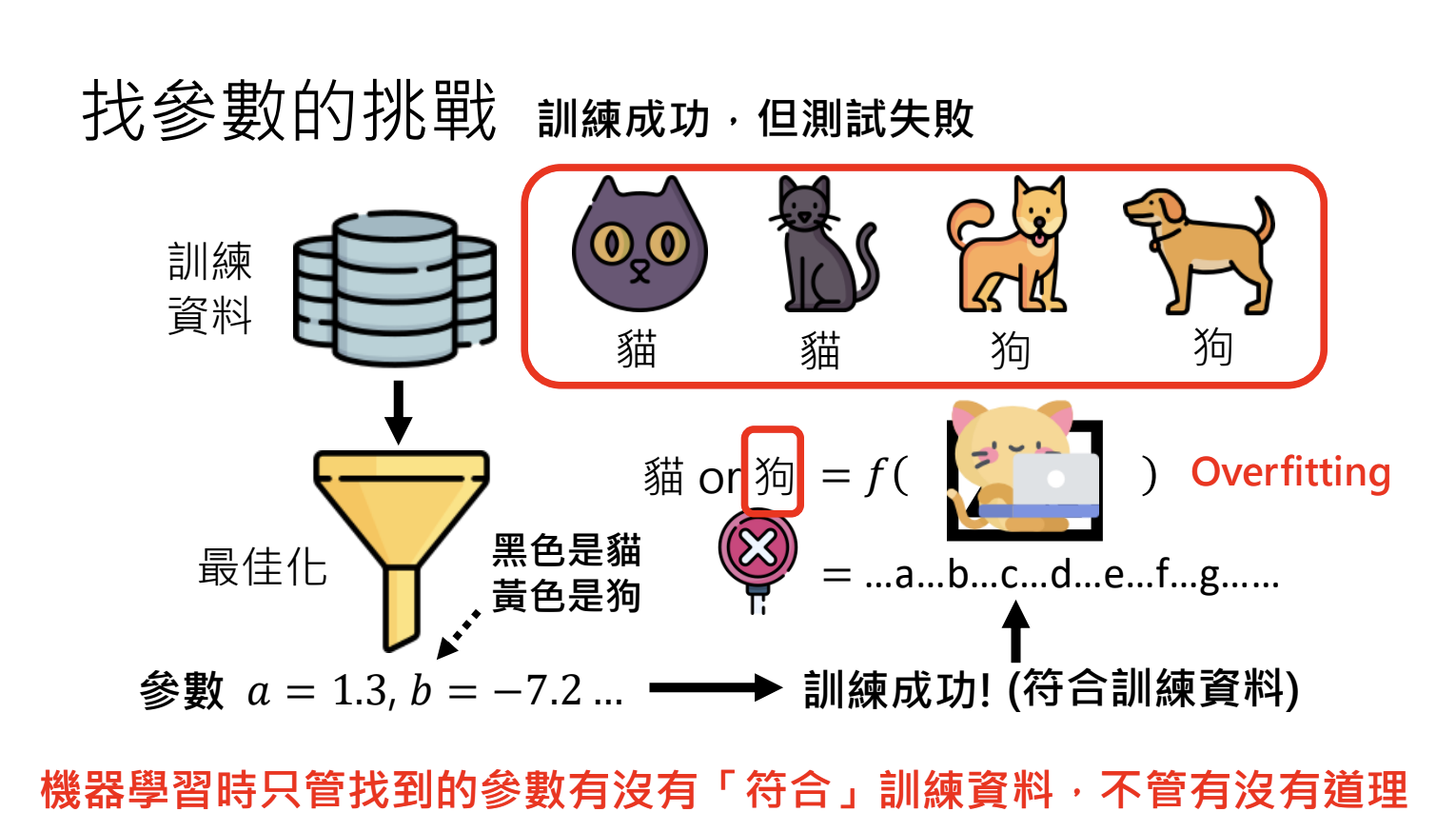
- 过度拟合(Overfitting):训练成功但是测试失败,找出的参数无法泛化(解决方式:增加训练资料多样性、设定合理初始参数)
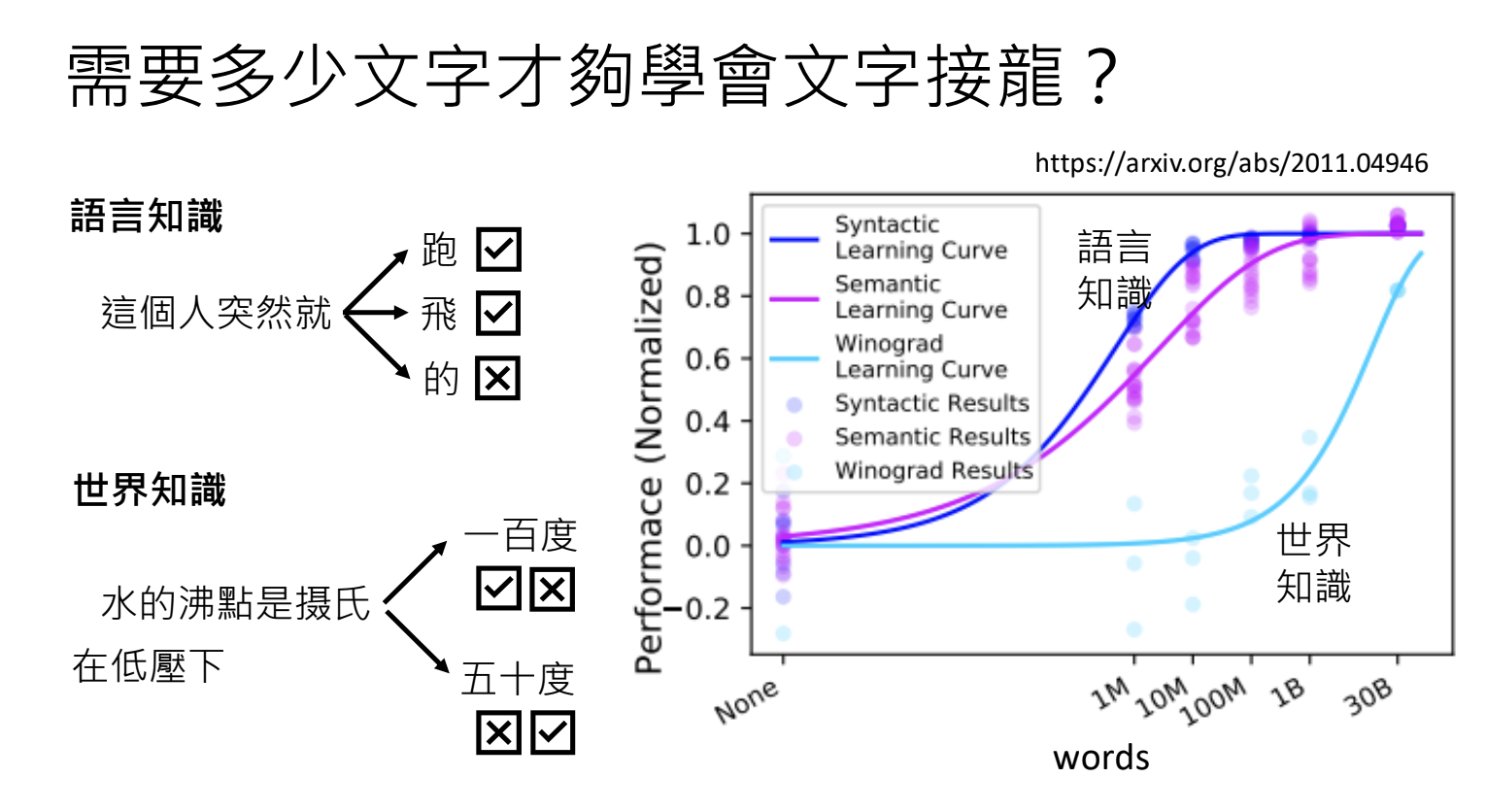
4.3.第一阶段:自我学习,积累实力
目标:通过大量文字资料,学习语言知识和世界知识;
资料来源:网络上爬取的文本资料;
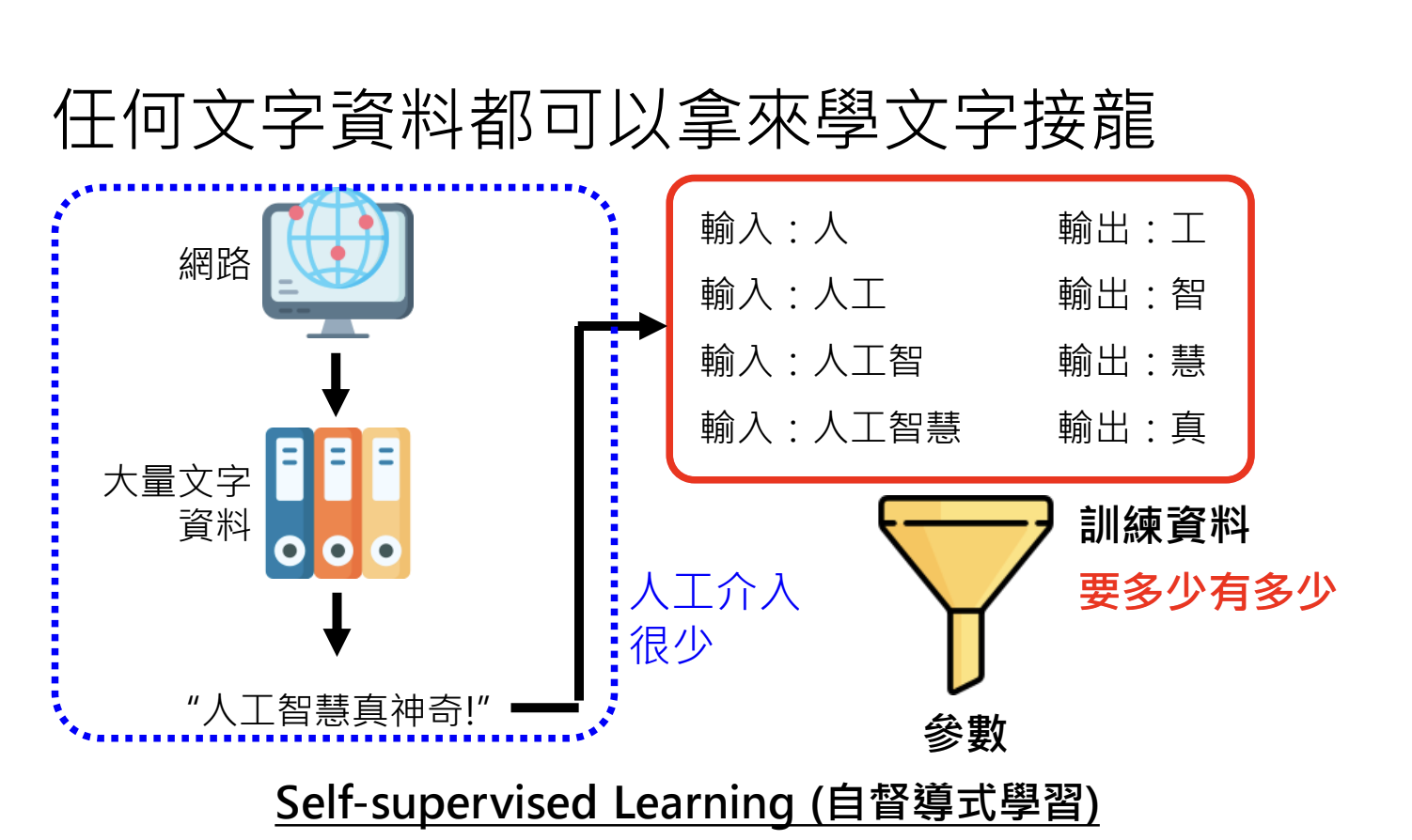
资料预处理:过滤有害内容、HTML标签、重复资料等;
自监督式学习(Self-supervised learning):少量人工介入

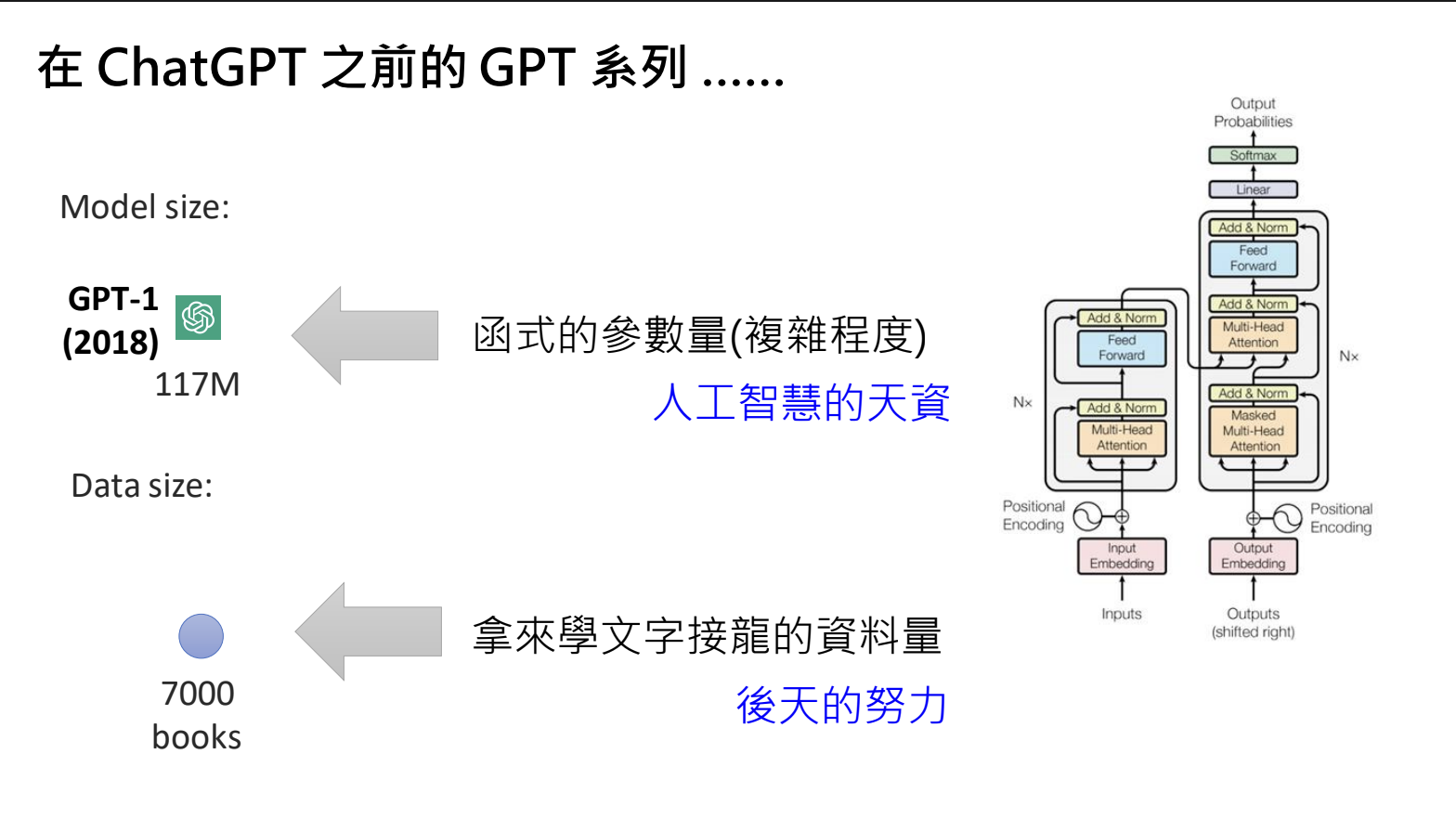
GPT系列模型(GPT-1 → GPT-3):
- 参数量从1亿增加到1750亿;
- 训练资料从700本书增加到3000亿token量;
自我学习的限制:
- 模型学到的只是片段知识,无法有效利用;
- 需要透过人类指导,学习如何正确使用所学知识;

4.4.第二阶段:名师指点,发挥潜力
语言模型修炼的阶段
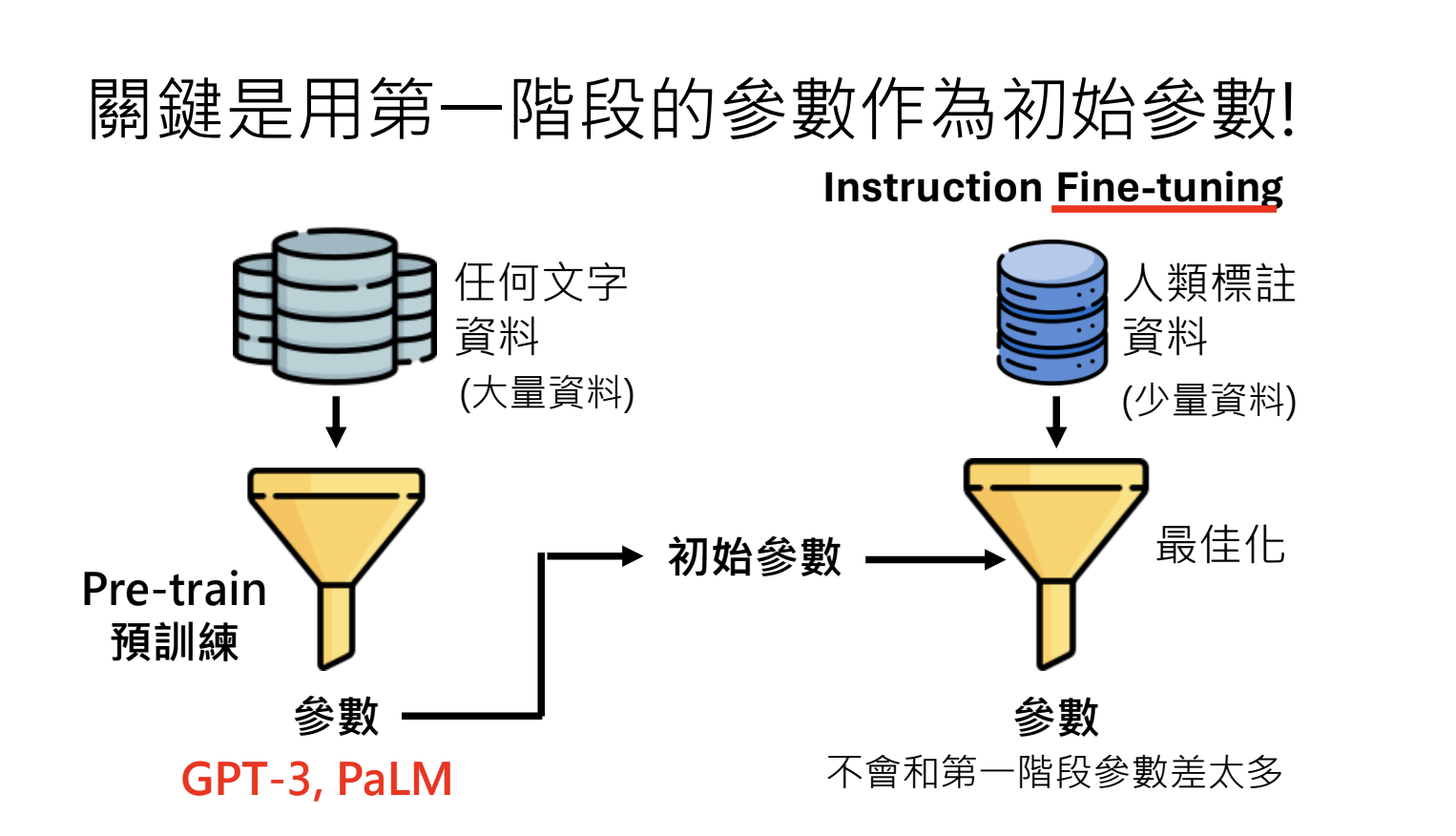
- 第一阶段:自我学习,通过网络上大量文字资料进行预训练(Pretain),获得复杂规则与知识(有利于微调transfer learning,并提供举一反三的能力);
- 第二阶段:通过人类标注的 instruction fine-tuning 资料,发挥语言模型潜力;
指令微调( Instruction Fine-tuning)
- 人类准备标注资料(问题+答案)供模型学习;
- 让模型按指令给出正确回应;
- 构建在于使用第一阶段预训练的参数当作初始参数;
- 可使用 Adapter 技术稳定参数;
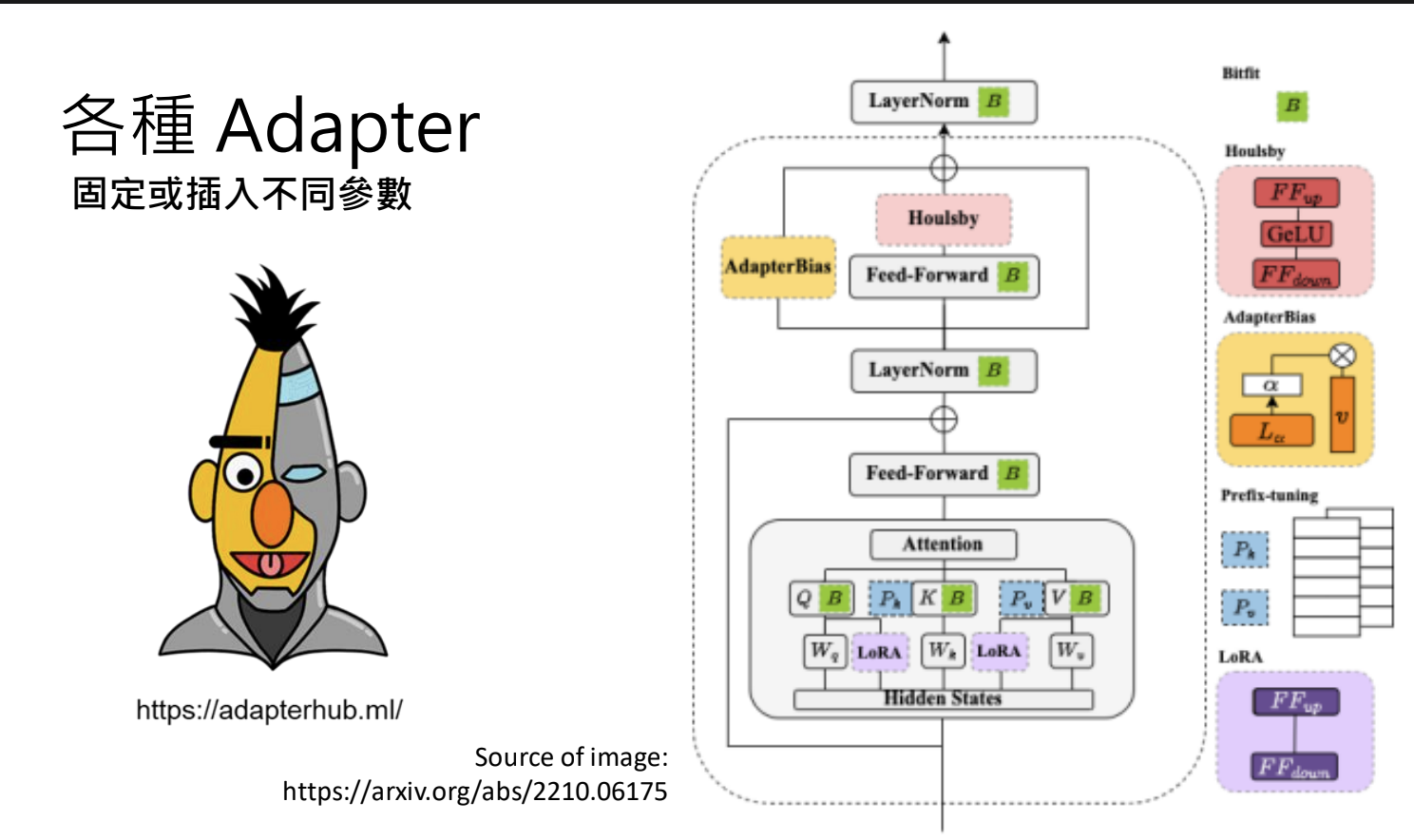
打造专才 vs 通才
- 专才:针对单一任务做 Fine-tuning(translator、editor等),如BERT;
- 通才:使用多种任务资料做 Instruction Fine-tuning;
指令微调资料收集
- 直接收集真实使用者问题并标注答案胜过死板范本(OpenAI做法);
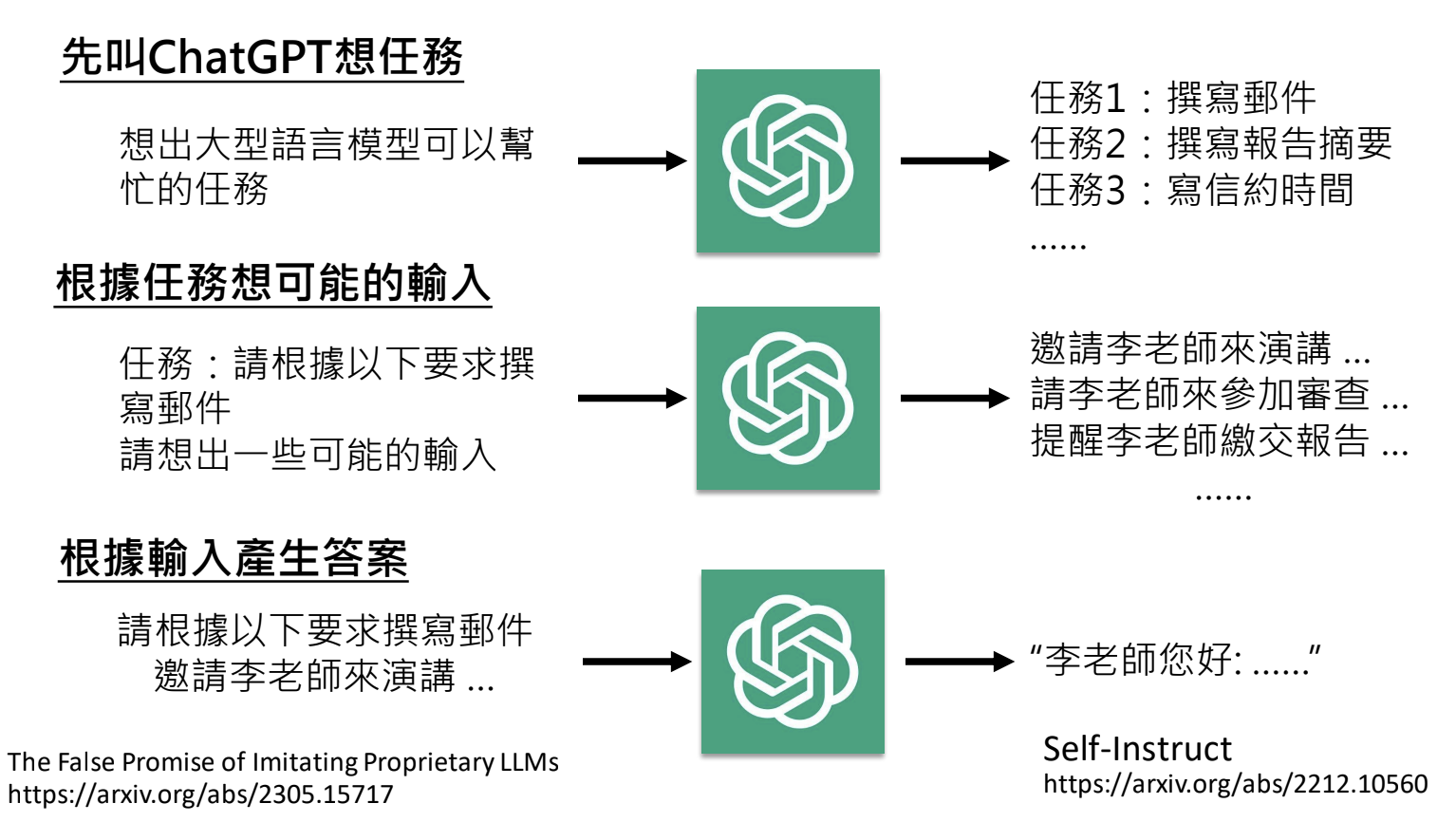
- 对ChatGPT等大型模型做逆向工程,生成问答(资料品质不佳,比没有要好);
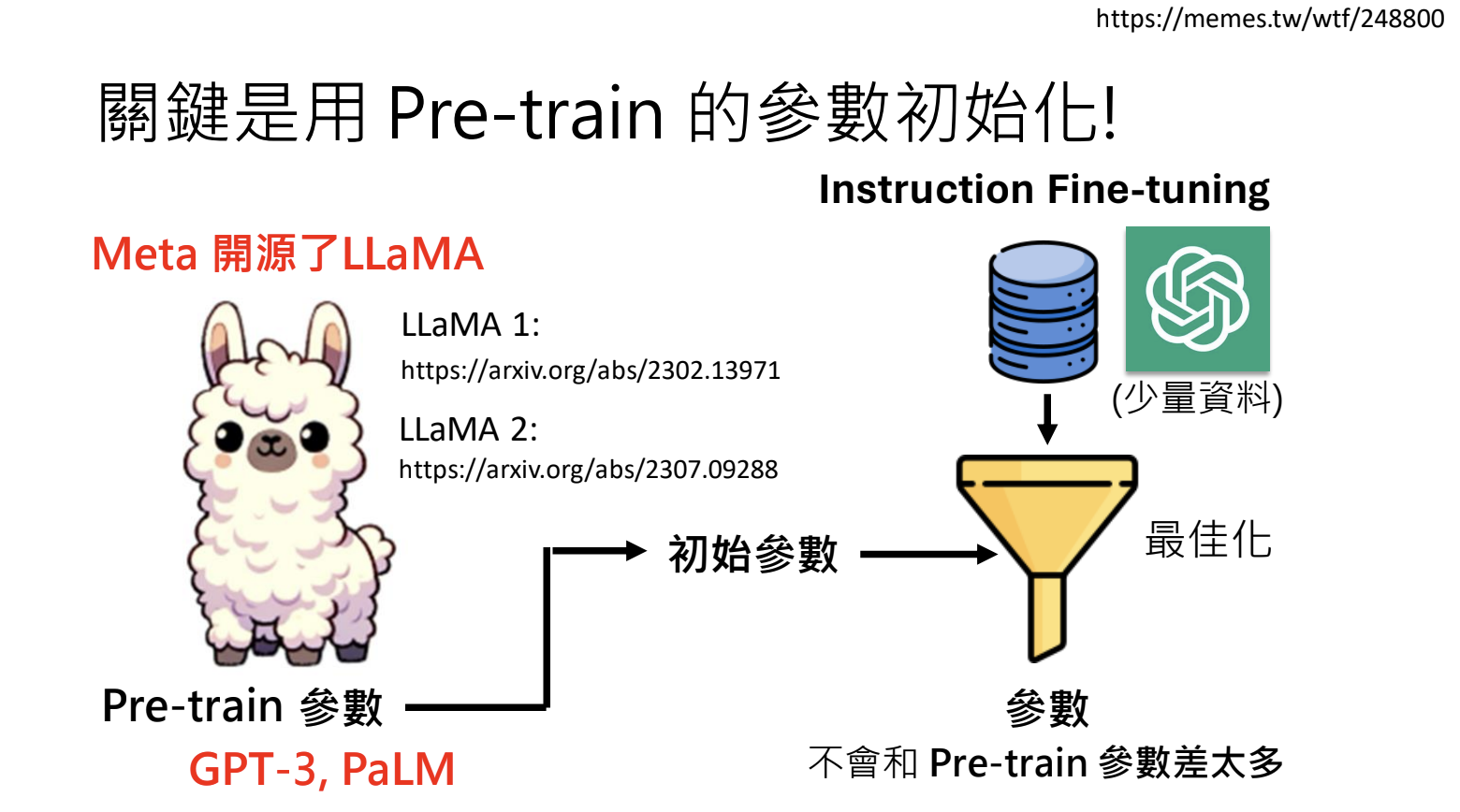
小模型
- LIama 模型的开源,使得个人/小团队都可以训练自己的大型语言模型;
- 不需要大量的资料来进行训练;
4.5.第三阶段:参与实战,打磨技巧
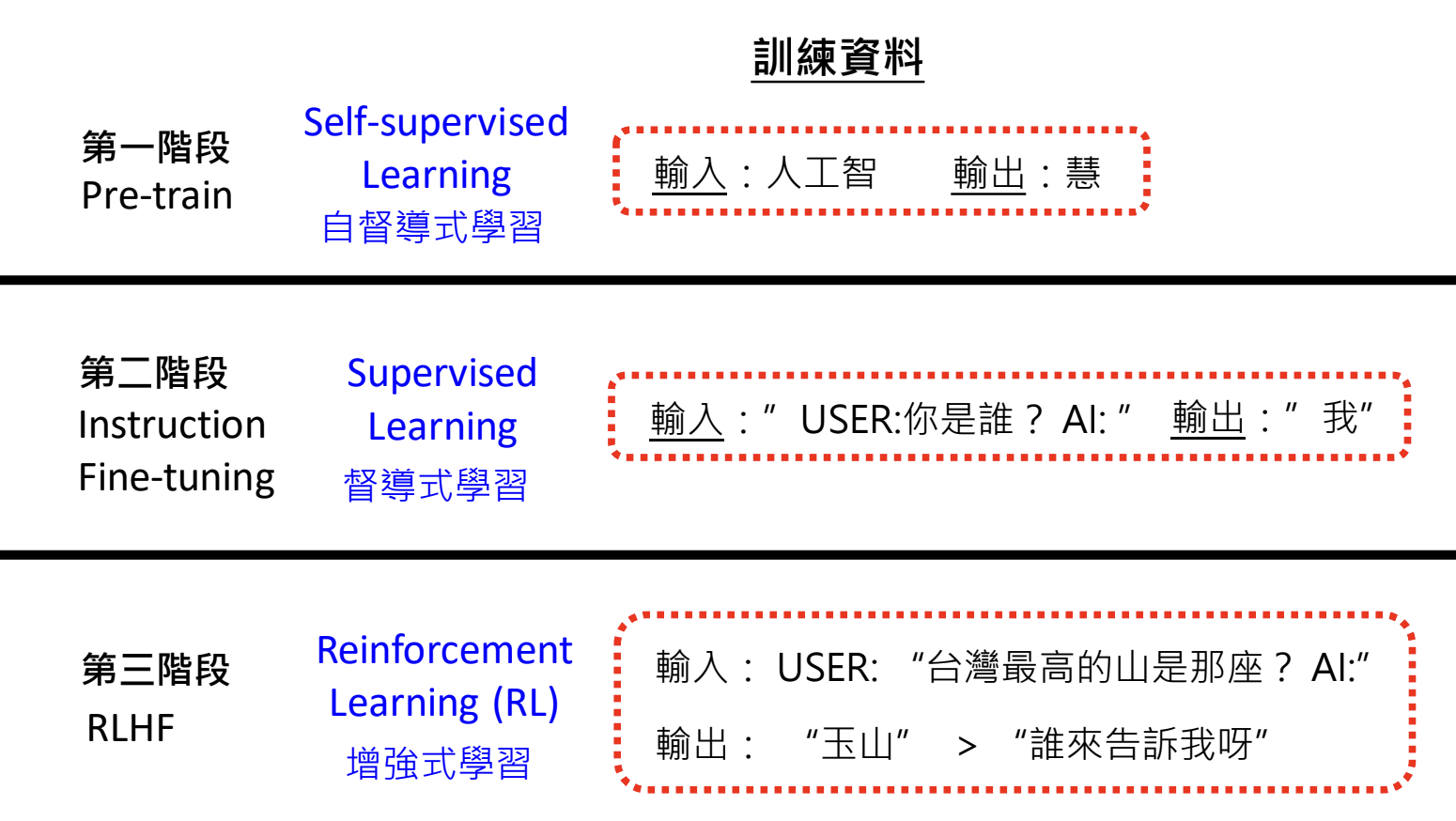
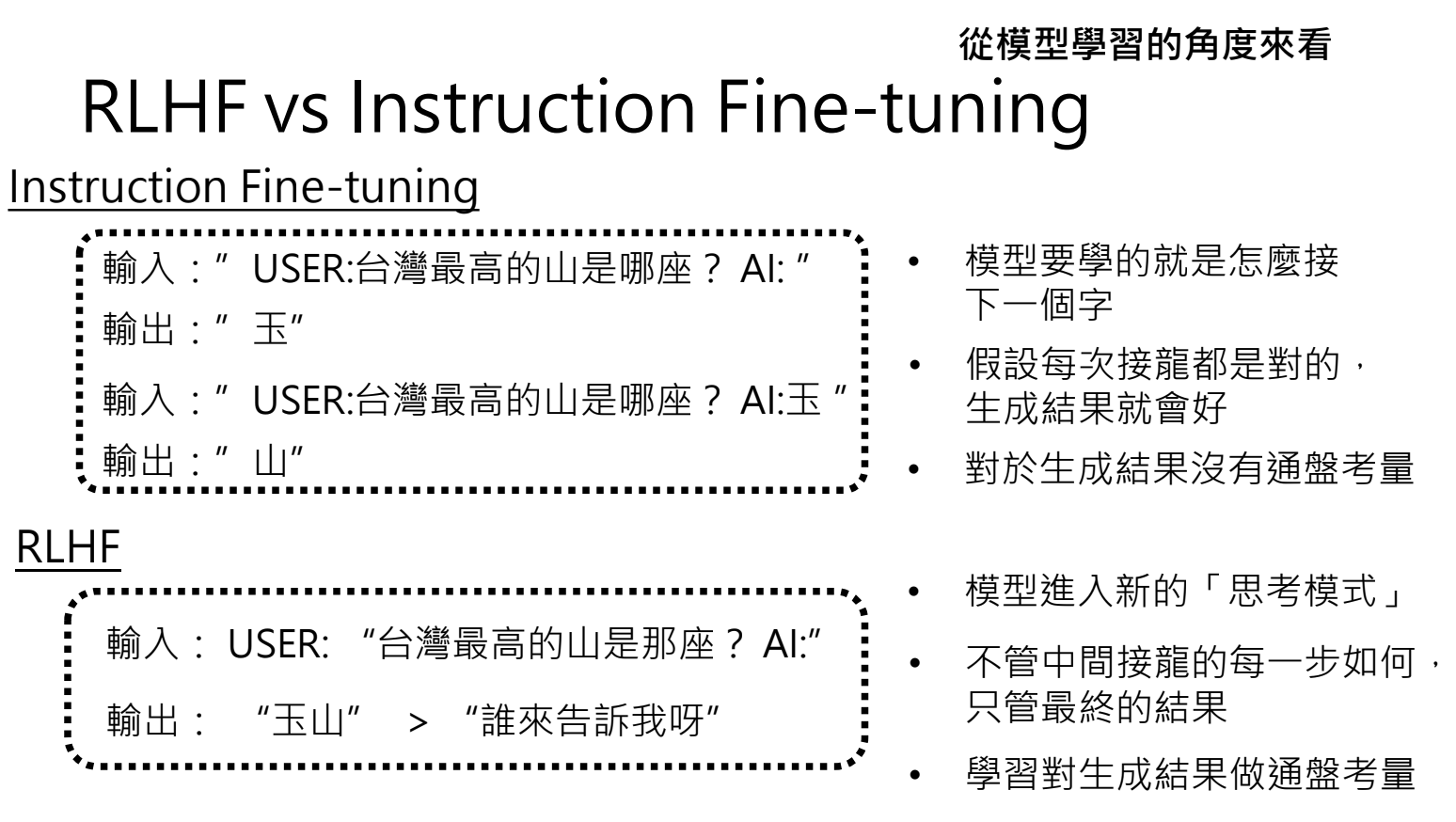
大模型训练第三阶段:互动及技巧学习(RLHF)
RLHF(Reinforcement Learning from Human Feedback):模型根据用户反馈进行学习与调整。
运作模式:语言模型根据反馈调整参数,提高好答案的生成概率,降低坏答案的生成概率;
例子:使用者对模型给出的答案不满意时,可要求模型重新生成答案,并提供反馈。
训练资料差异
- 第一阶段:Pre-traning,使用网络获取资料;
- 第二阶段:Intermediate Pre-traning,资料由人提供,称为 Supervised Learning;
- 第三阶段:RLHF 增强式学习,训练资料不再是明确的输出,而是相对好坏的评价。
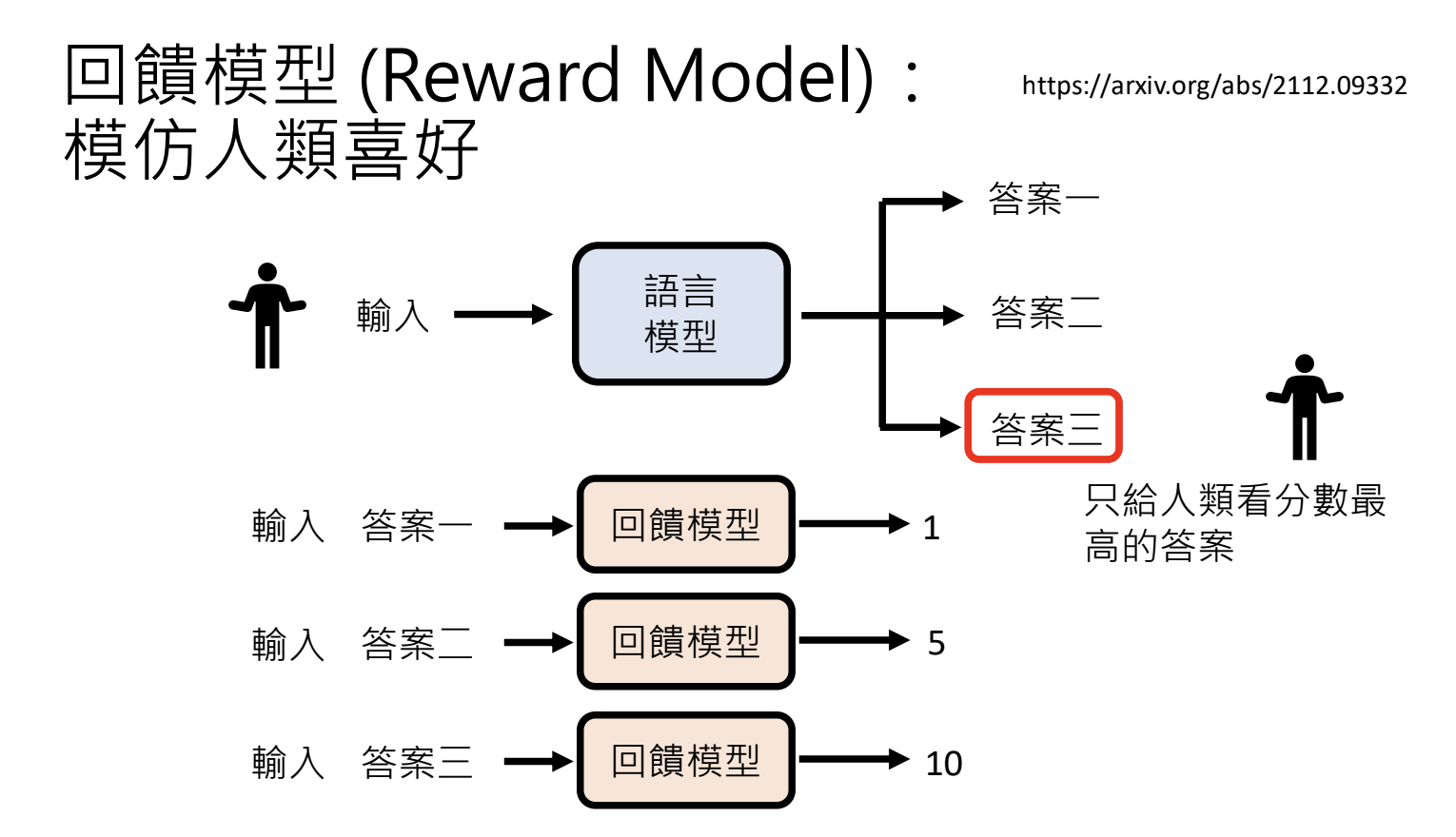
RLHF的实际应用
使用回馈模型(Reward Model)来模拟人类反馈,进行模型训练。
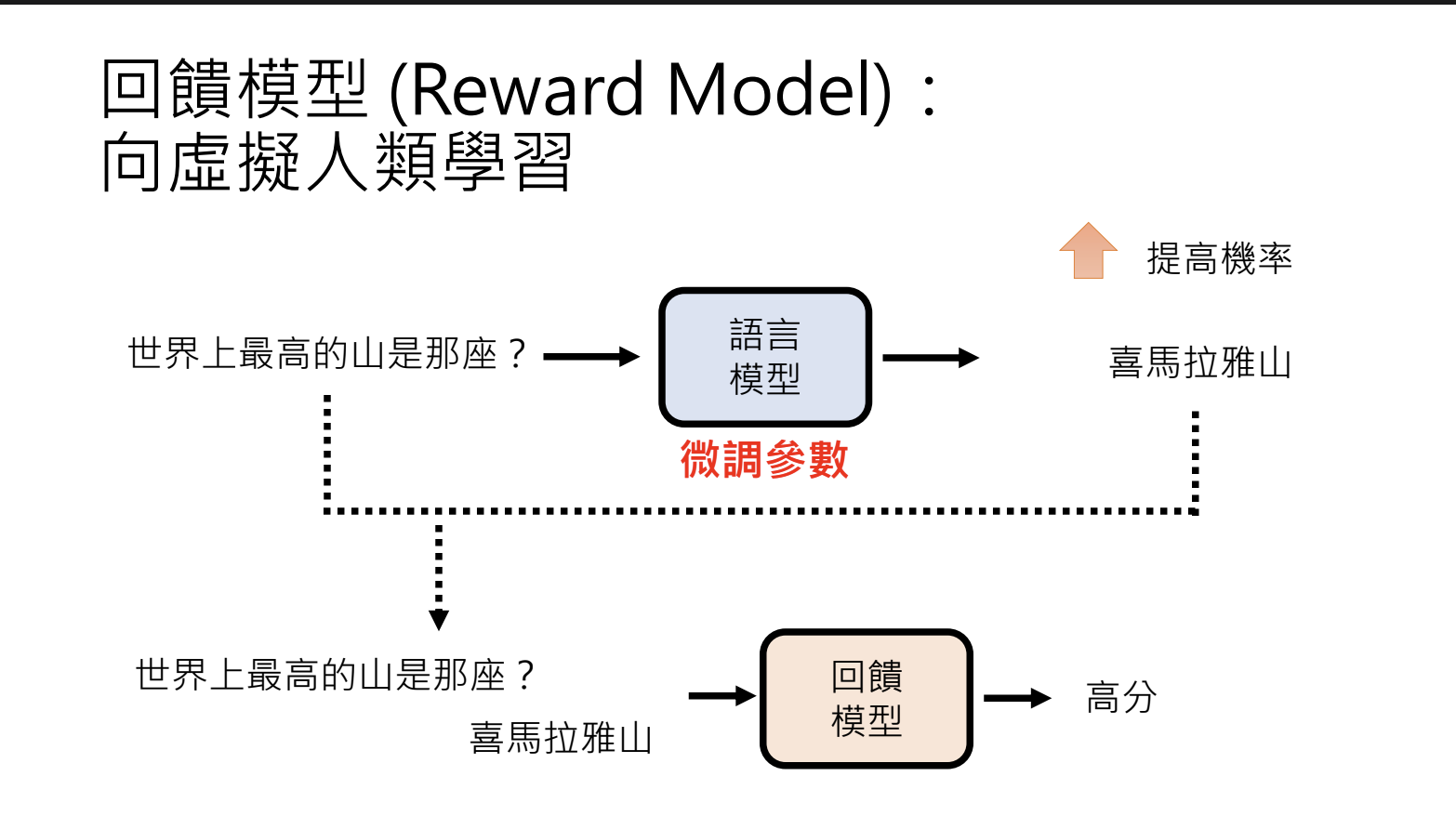
训练模型的演进
从AI-Human Feedback 到 AI-AI Feedback,使用AI模型相互提供回馈。
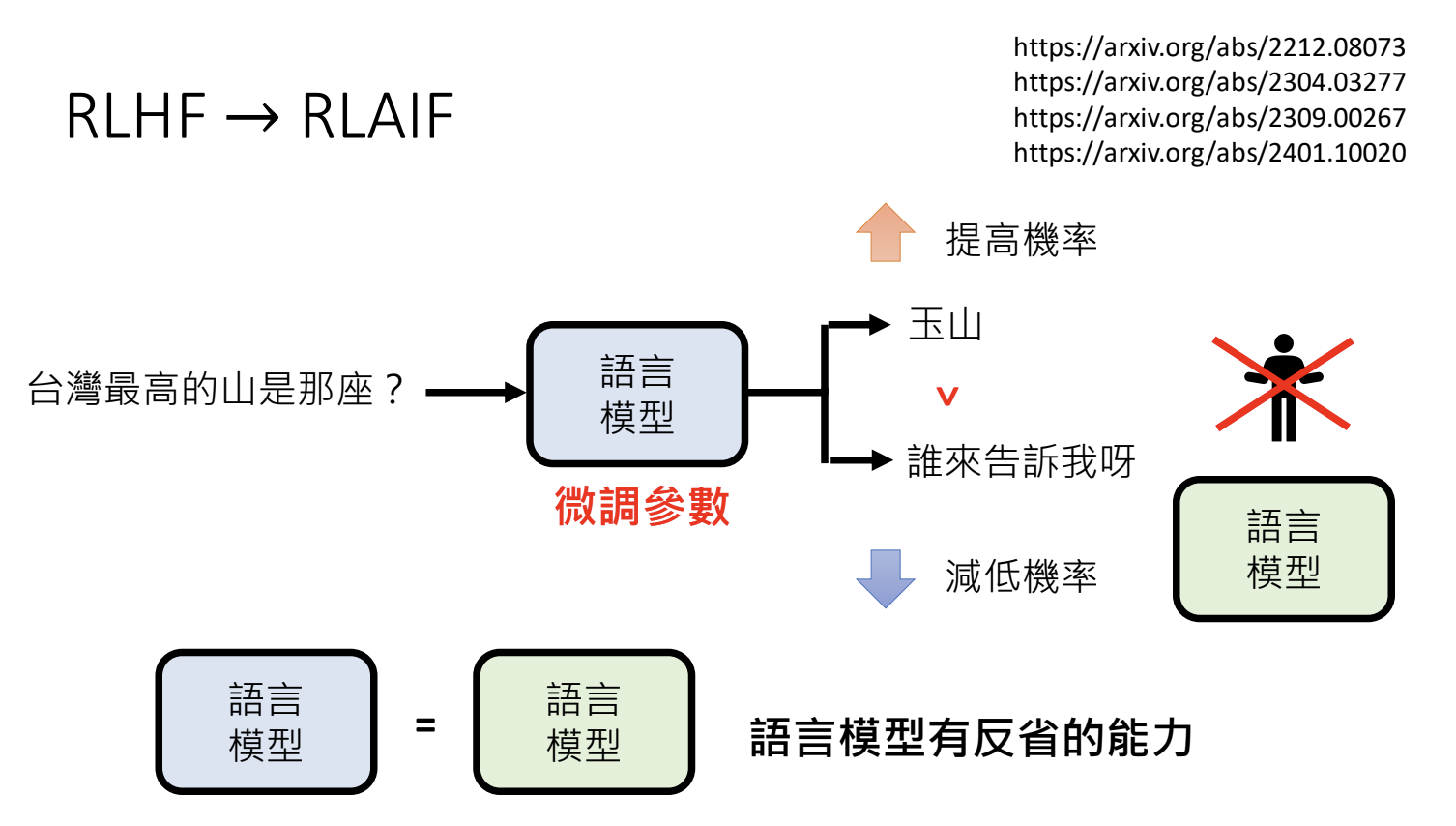
5.以大语言模型打造AI Agent
5.1.AI Agent定义
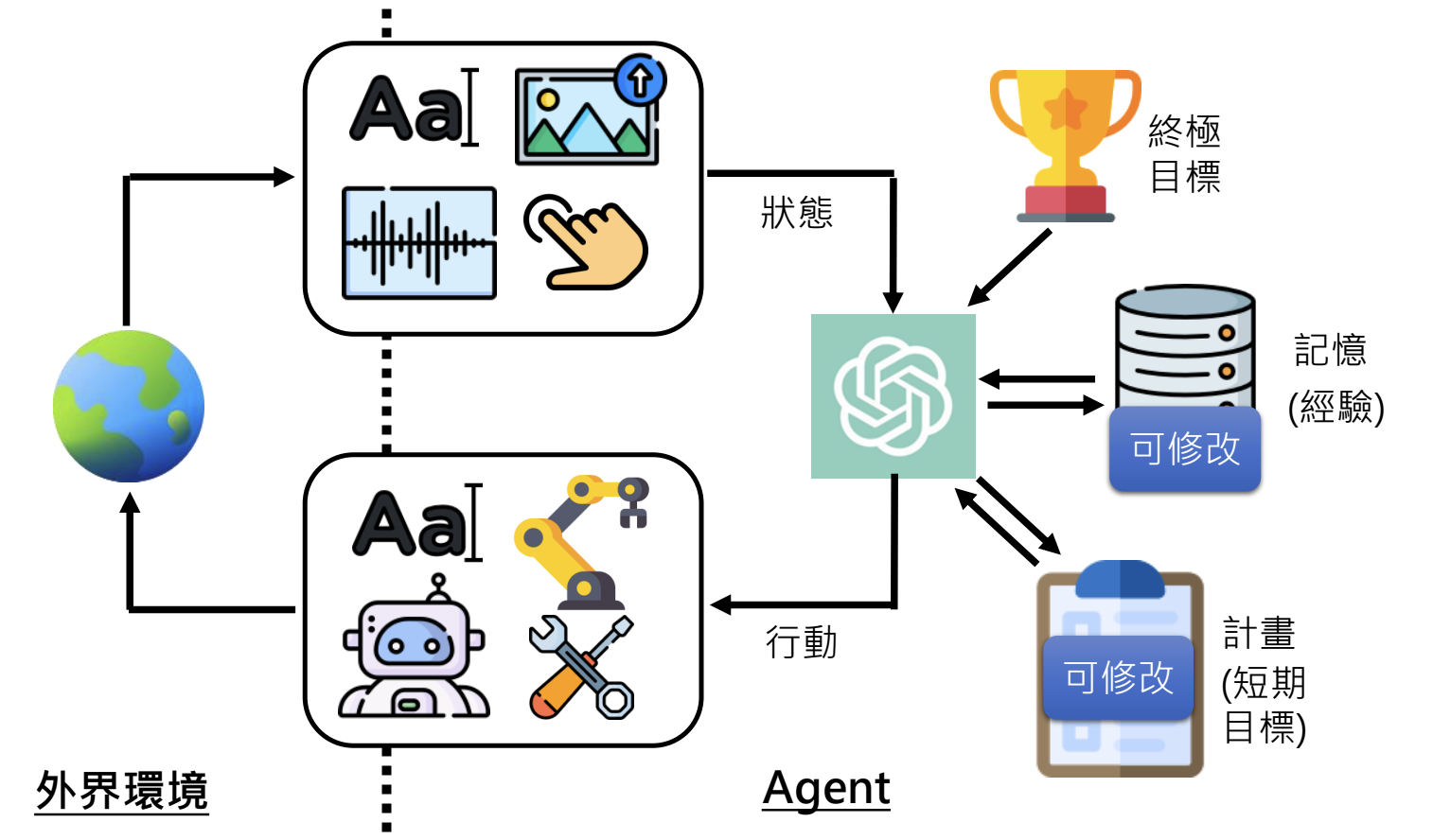
能执行多步骤复杂任务的AI,能够做计划并修改计划。
5.2.AI Agent运作原理
- 终极目标:AI Agent欲达成的任务;
- 记忆:过去与环境互动的经验;
- 感知:透过感官了解外界状态;
- 计划:根据目标、记忆、状态产生的短期目标和行动方案;
- 行动:根据计划进行的具体操作;
- 学习与适应:根据环境变化调整计划和记忆;
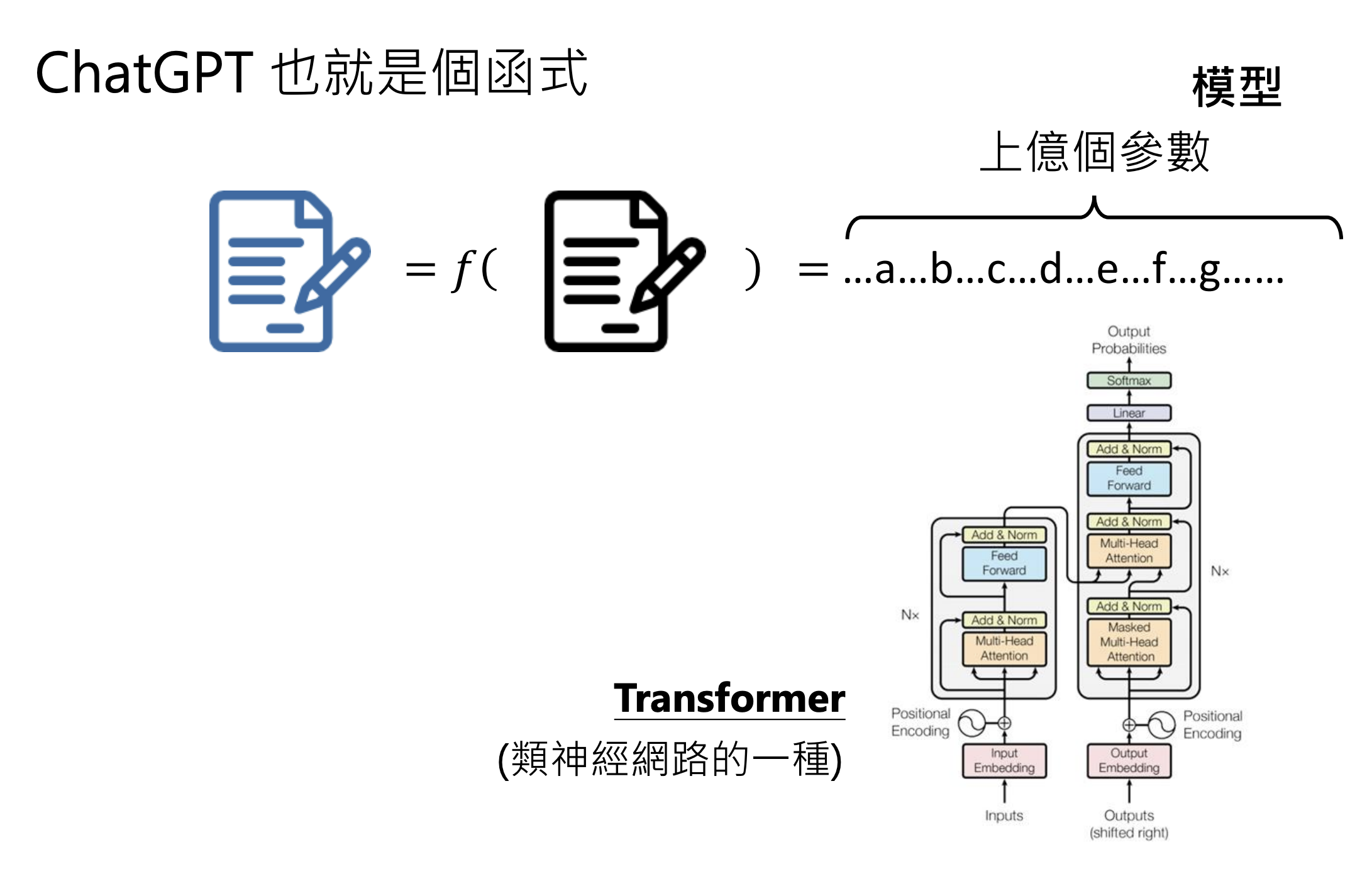
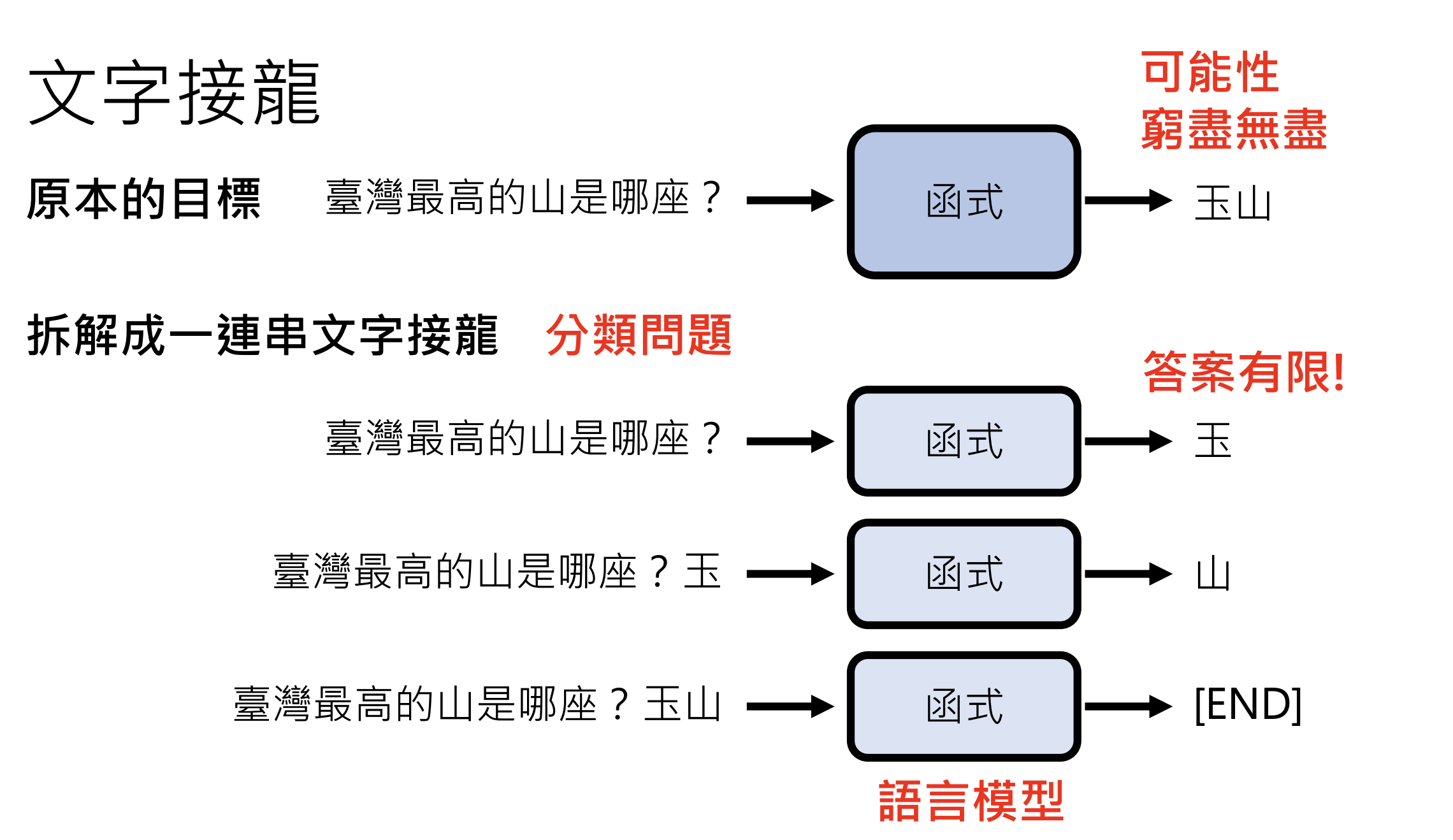
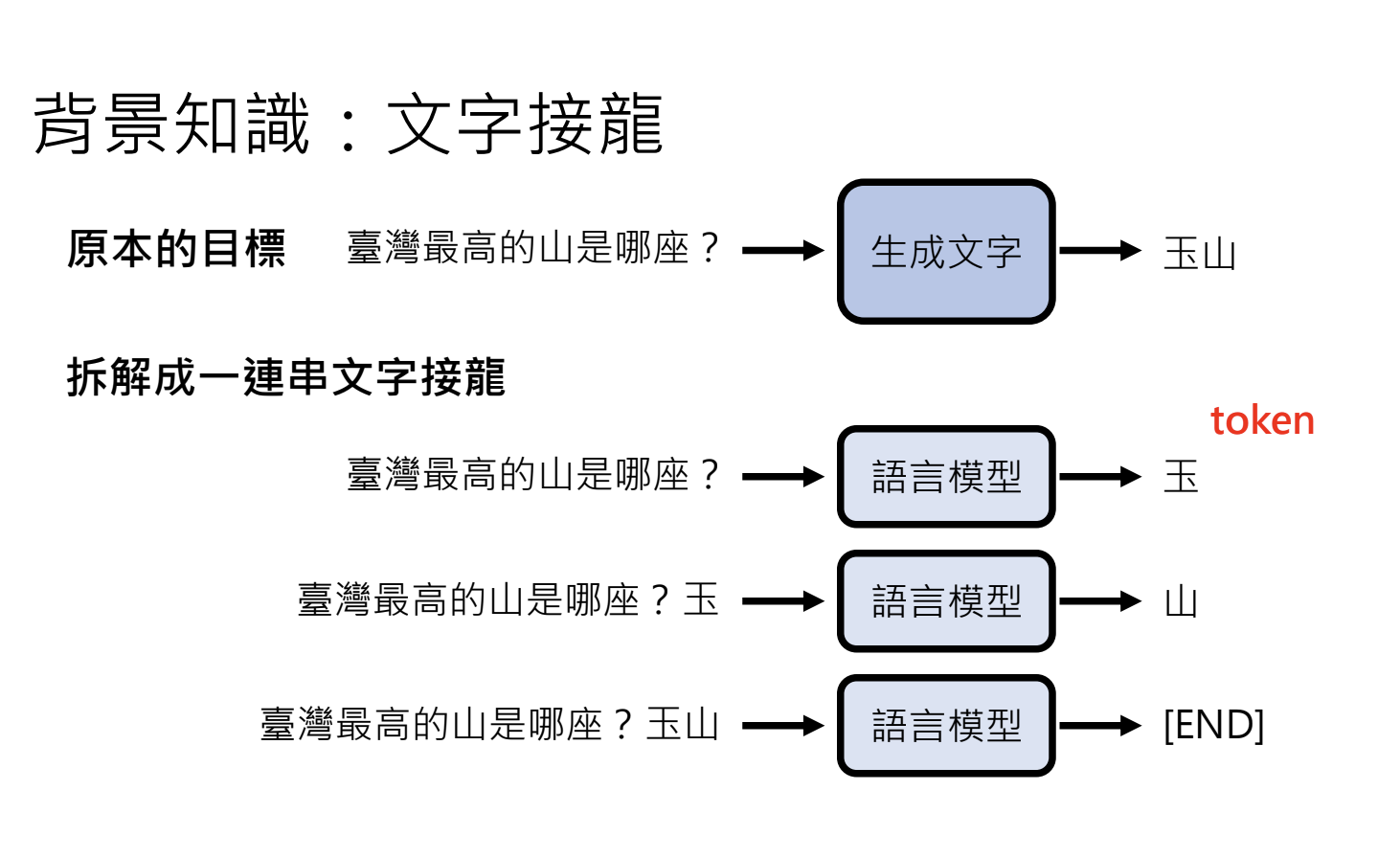
6.今日的大语言模型是如何做文字接龙的 - Transformer简介
6.1.模型的演进
N-gram —> Feed-forward Network —> Recurrent Neural Network(RNN) —> Transformer
6.2.Transformer概述
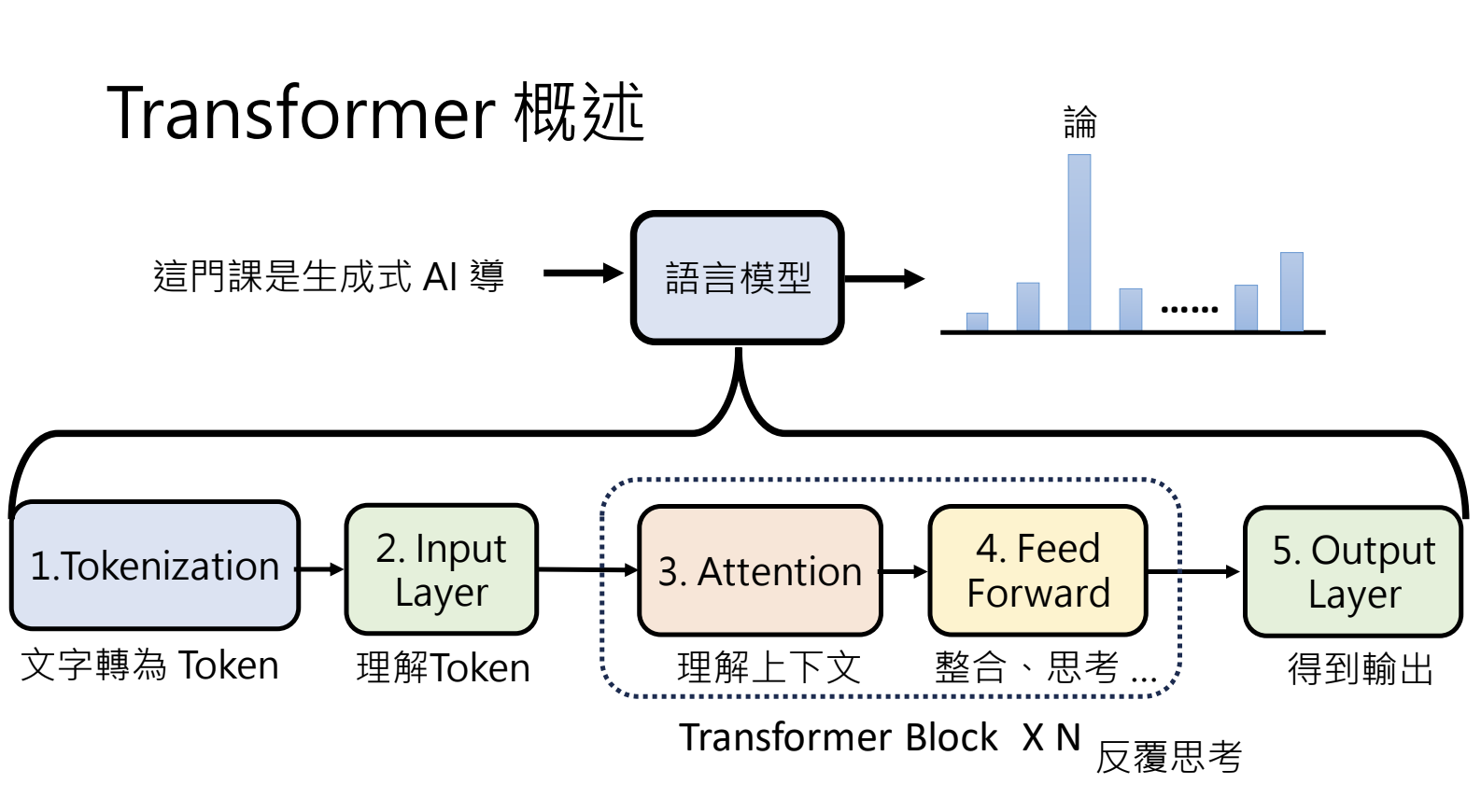
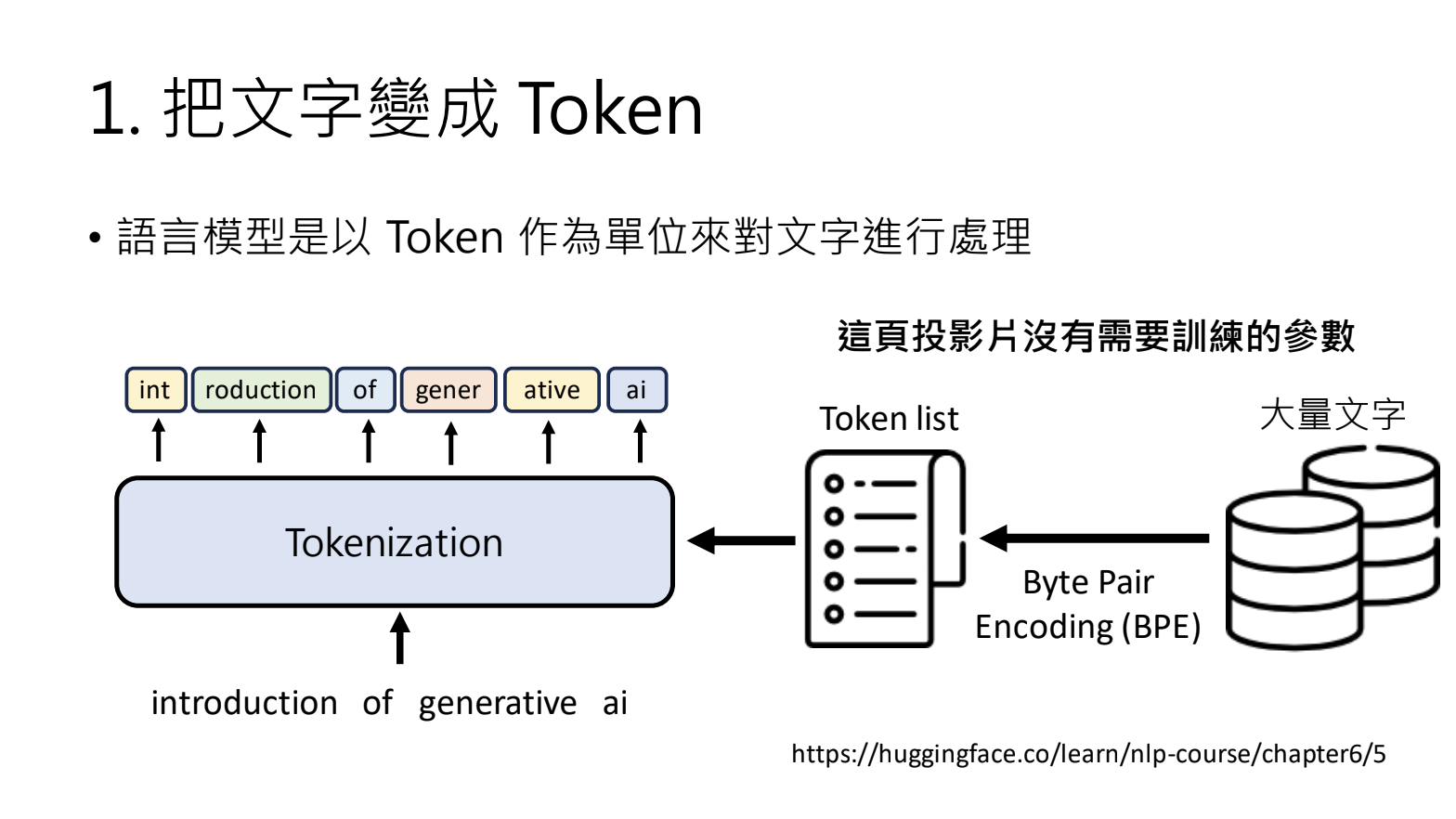
1.将文字变成Token
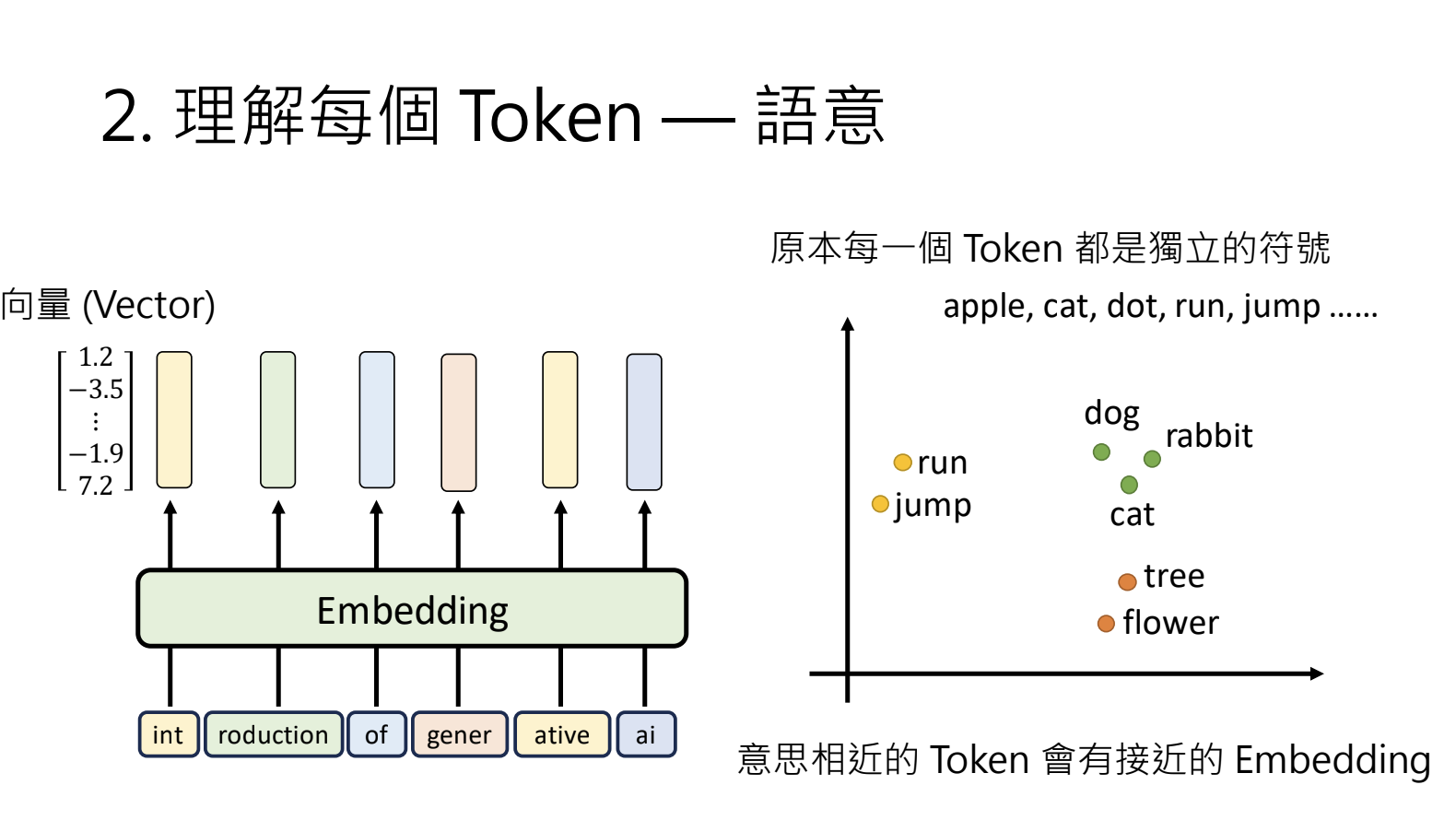
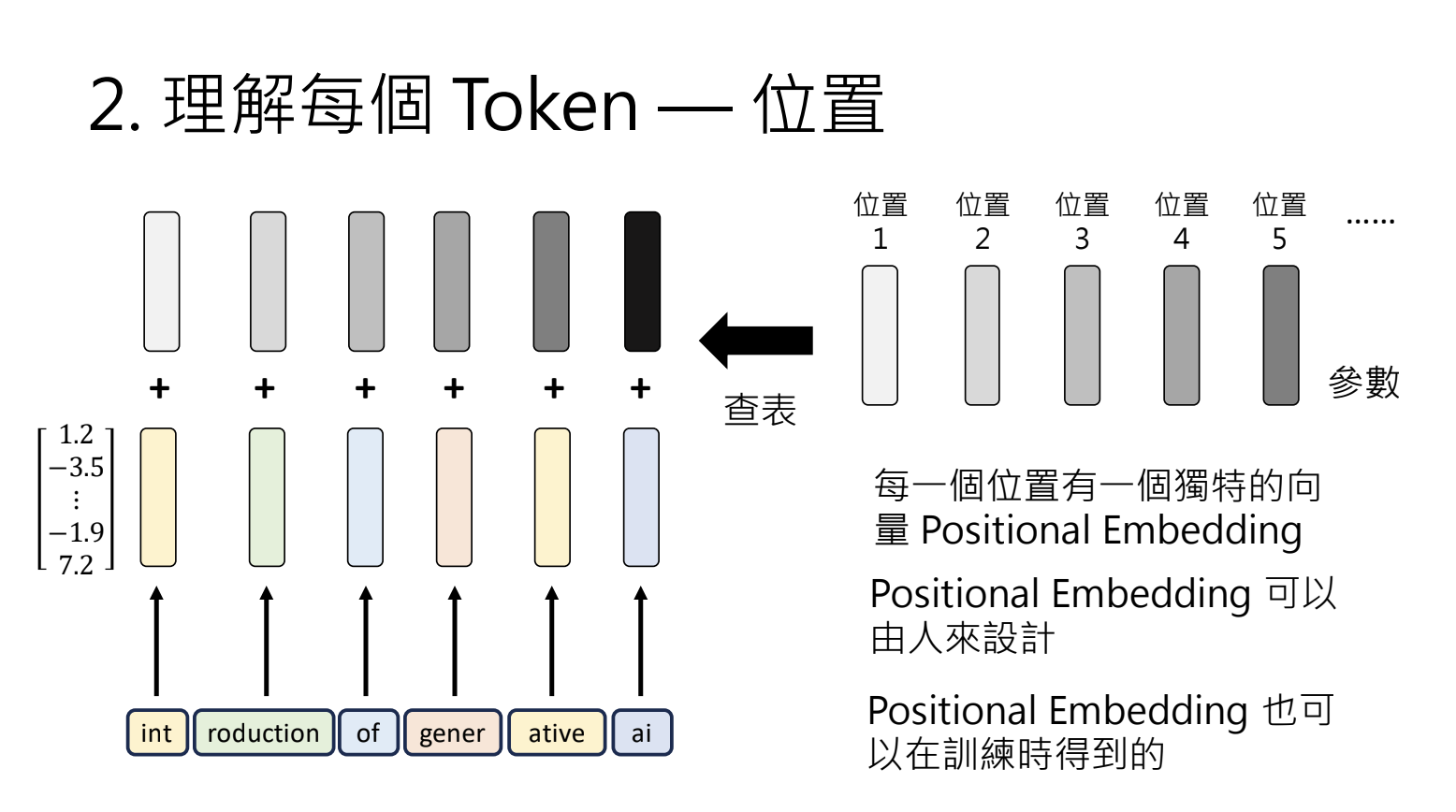
2.理解每个Token - 语意
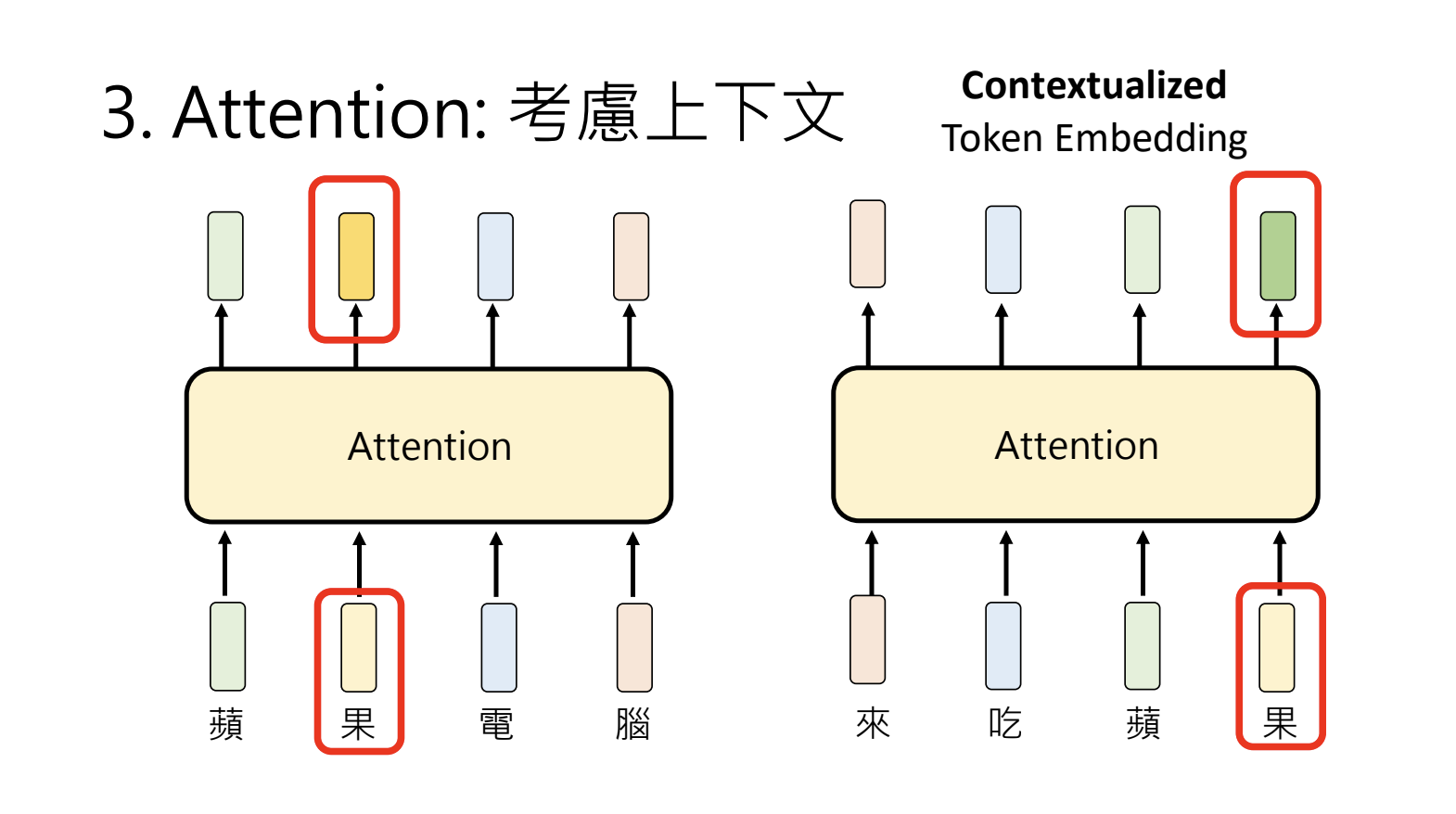
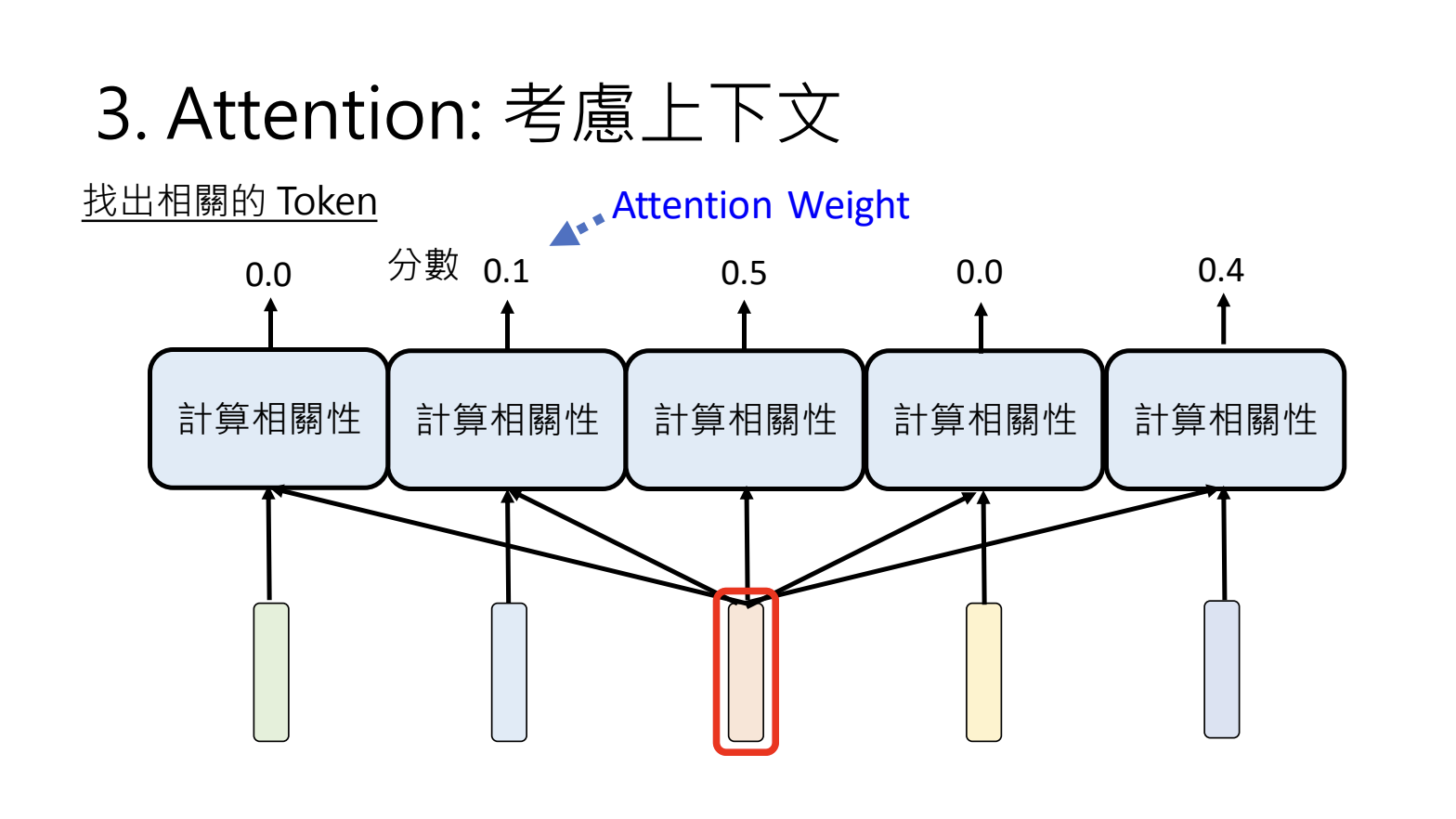
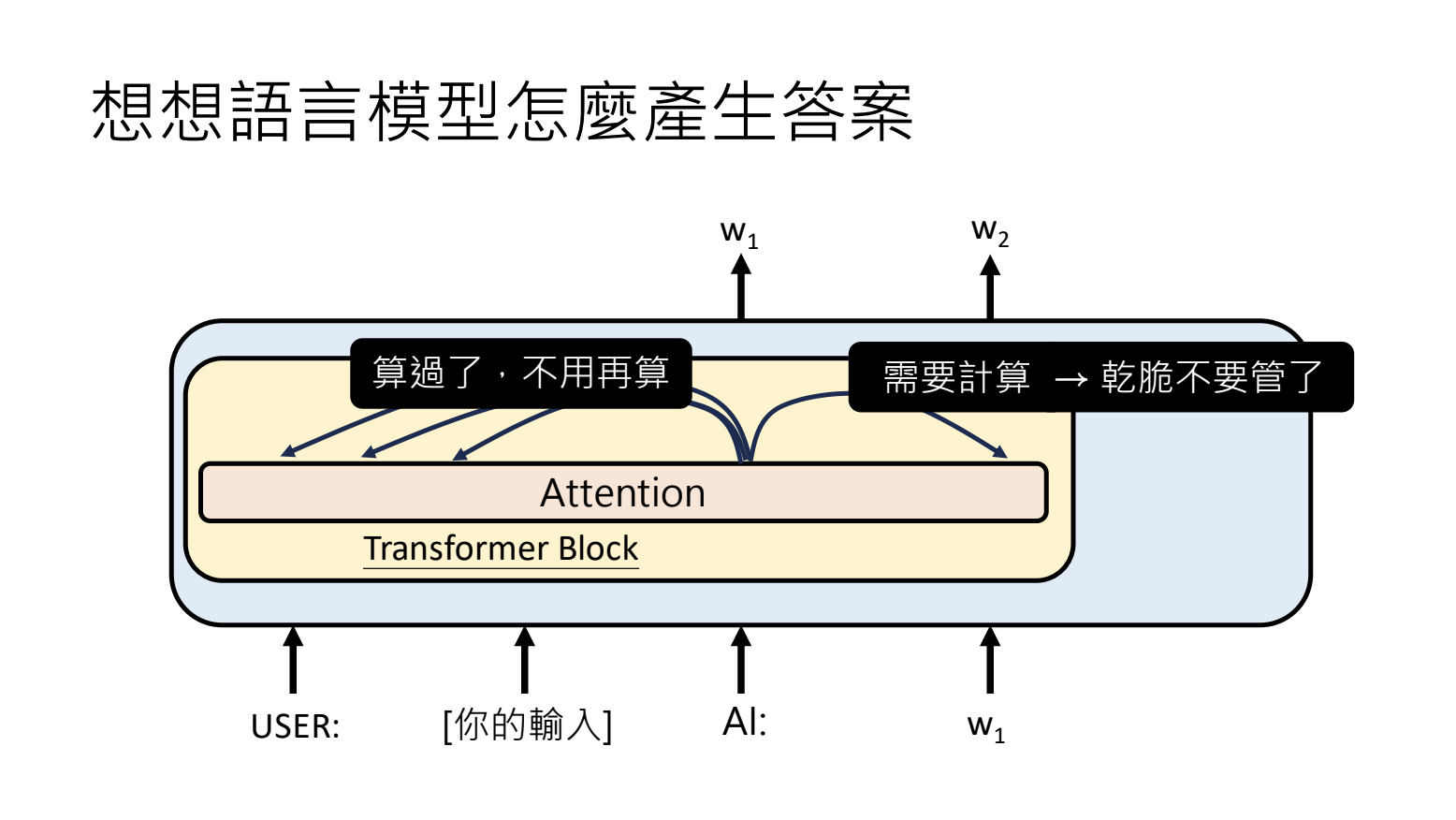
3.Attention:考虑上下文
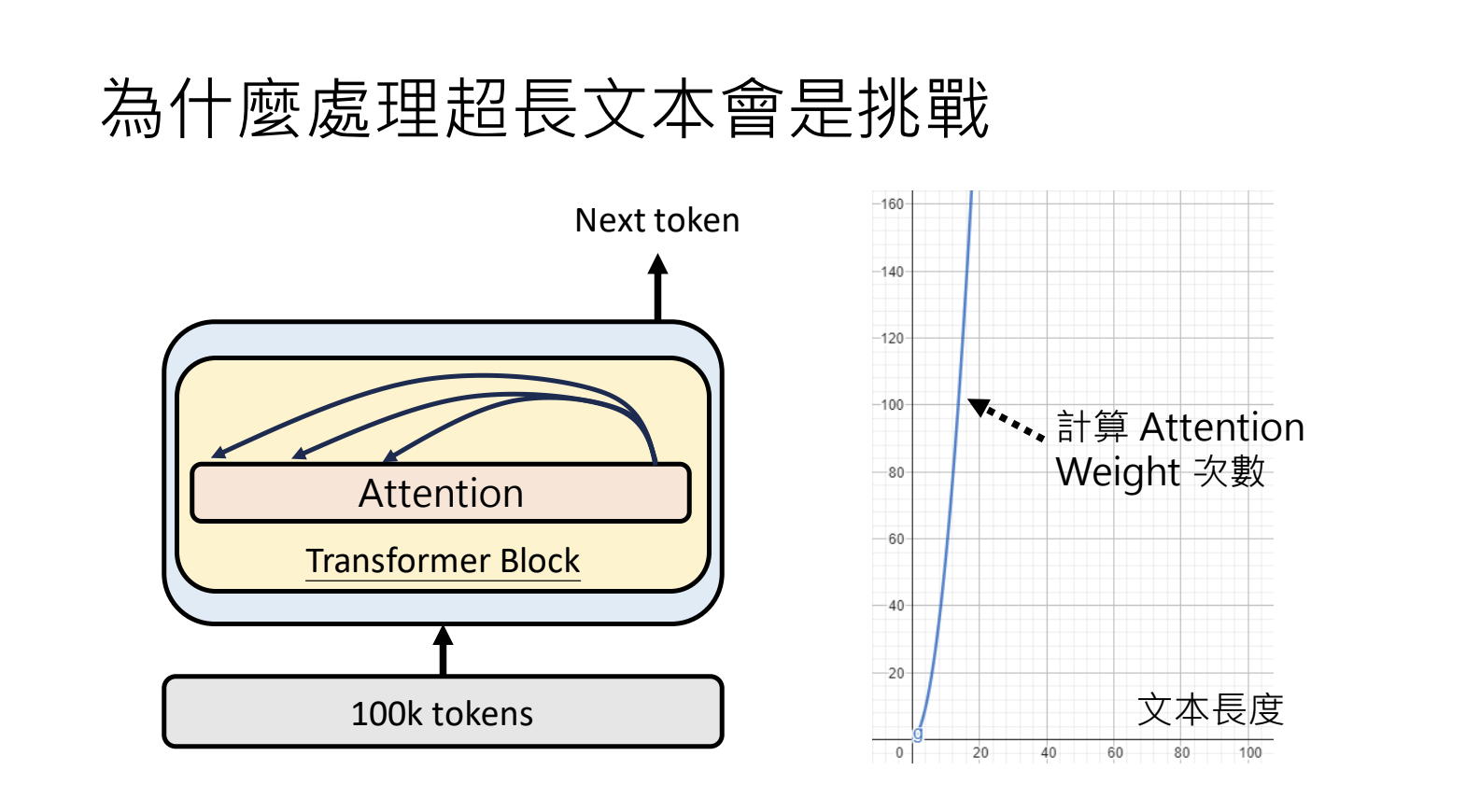
为什么处理超长文本会是挑战
7.大型语言模型在「想」什么呢
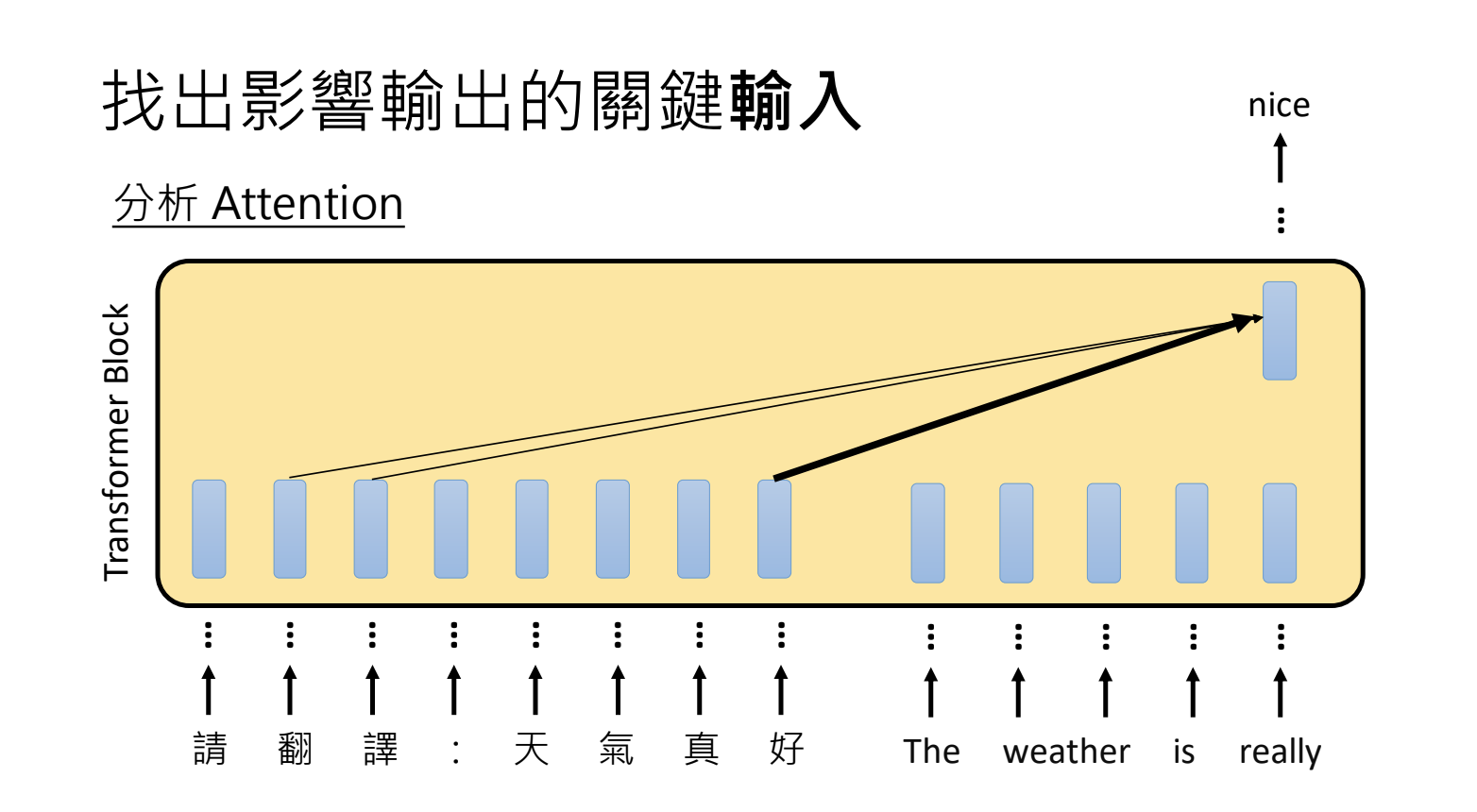
7.1.对类神经网络进行分析(开源模型)

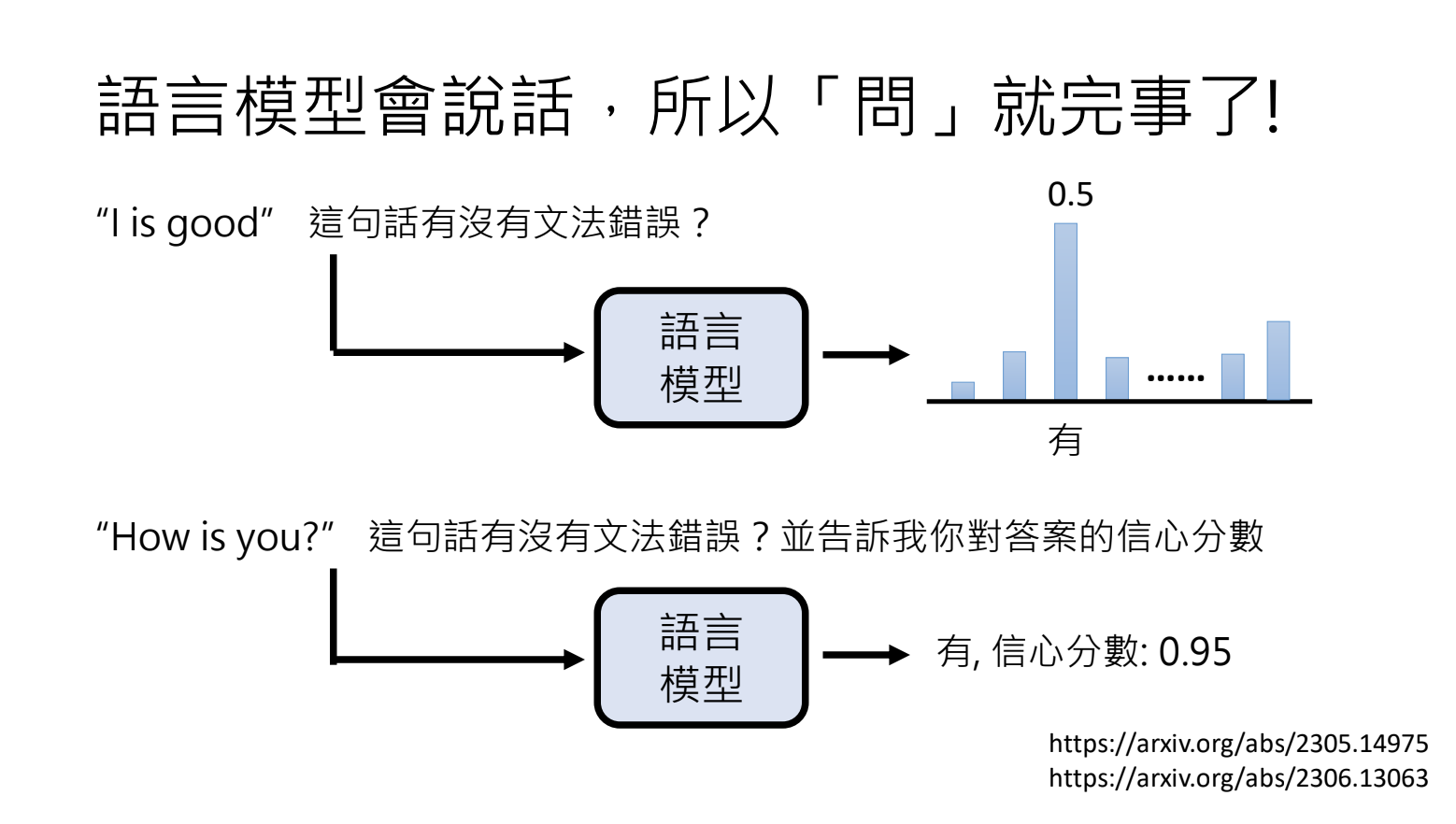
7.2.直接问语言模型为什么这样思考
但是语言模型提供的解释不一定可信,可以被误导;
8.语言模型能力鉴定
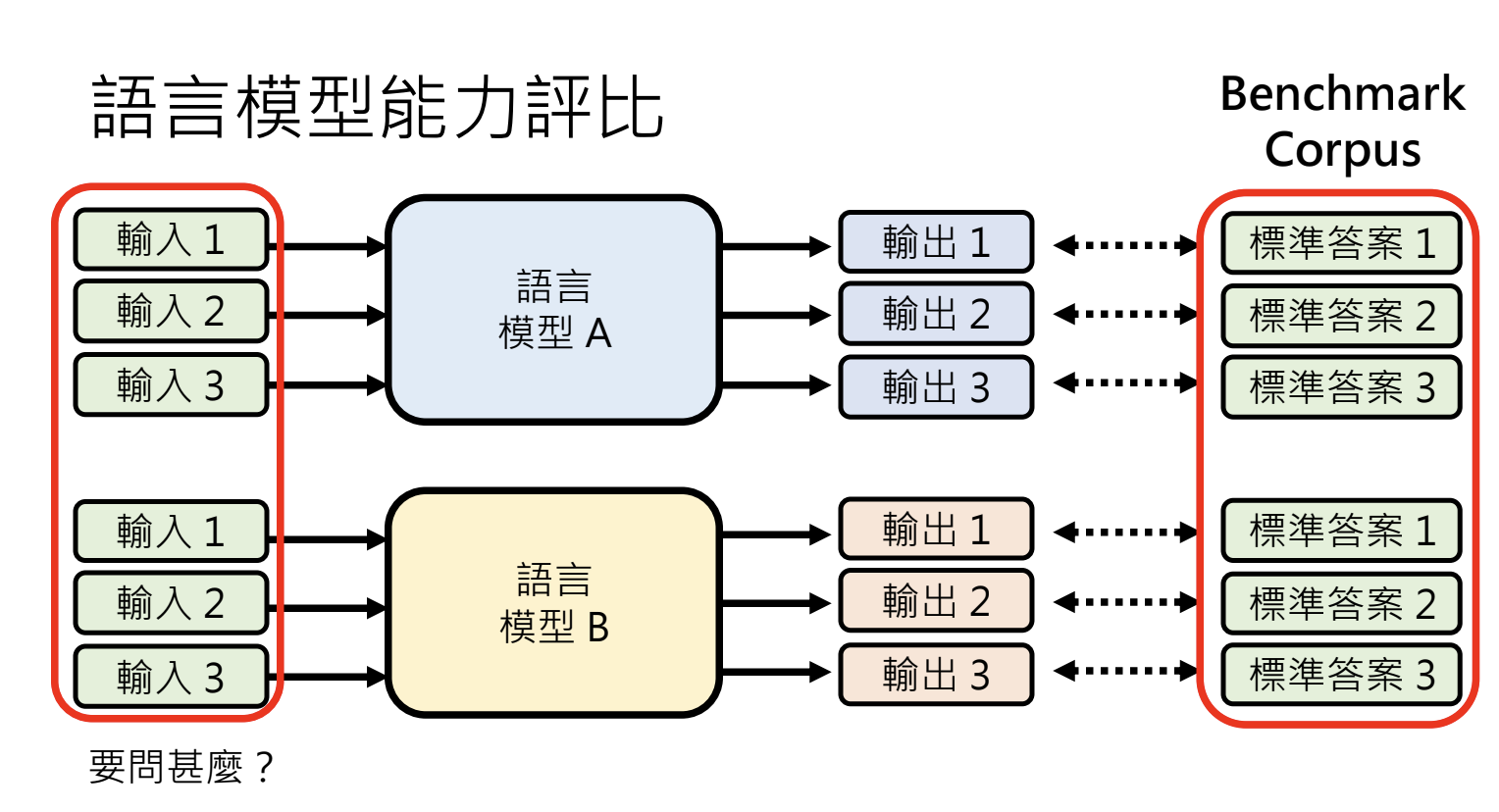
8.1.评比的方式
使用问问题对答案的方式来评比,除了选择题,还有阅读理解能力、处理长文本等多种。
- 核对答案时,标准性会受到选项顺序、输出格式等多种因素影响;
- 使用人工来判定,需要投入大量的资源;
- 让大模型来评估答案(如GPT-4);
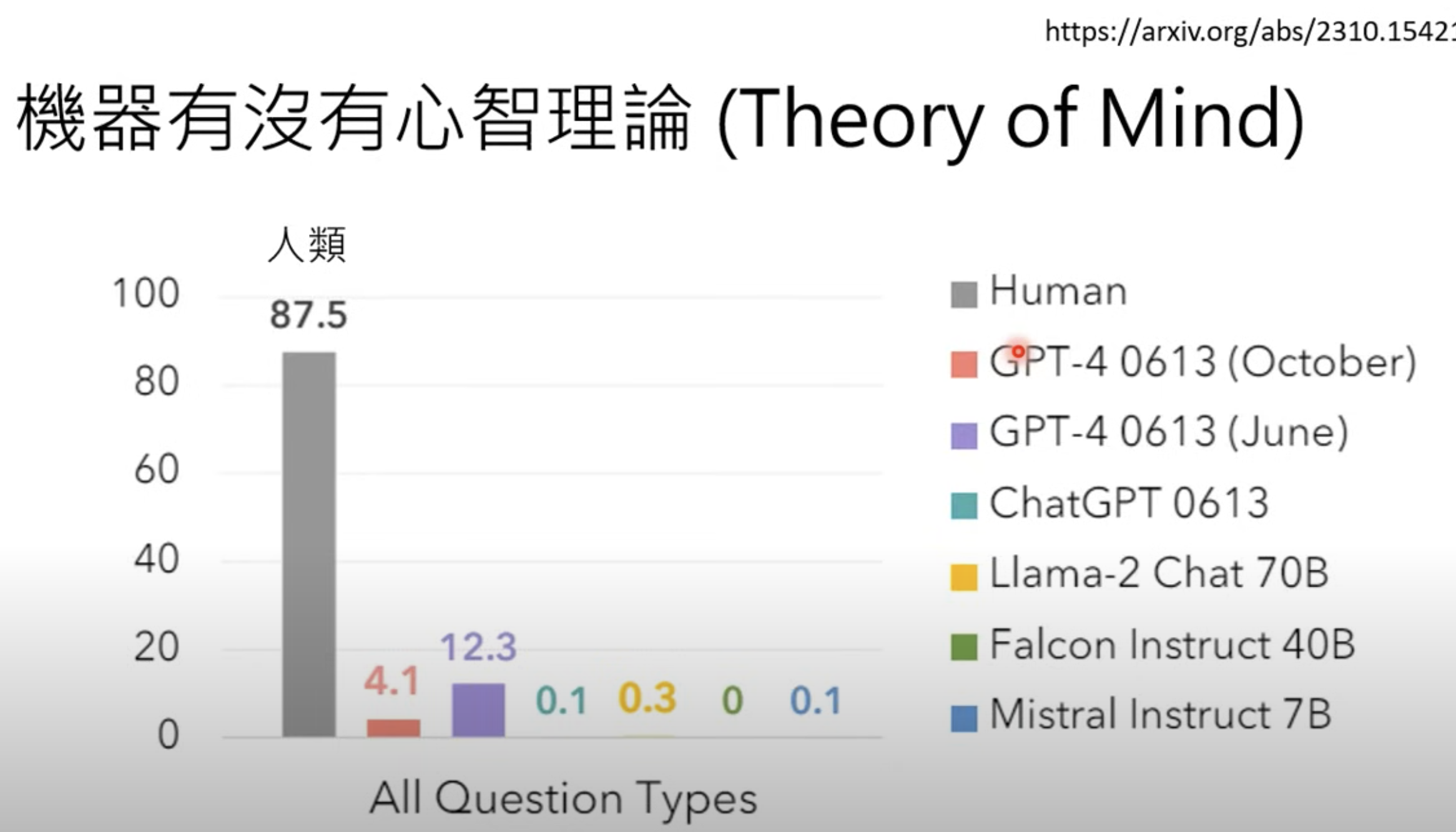
8.2.机器有没有心智理论
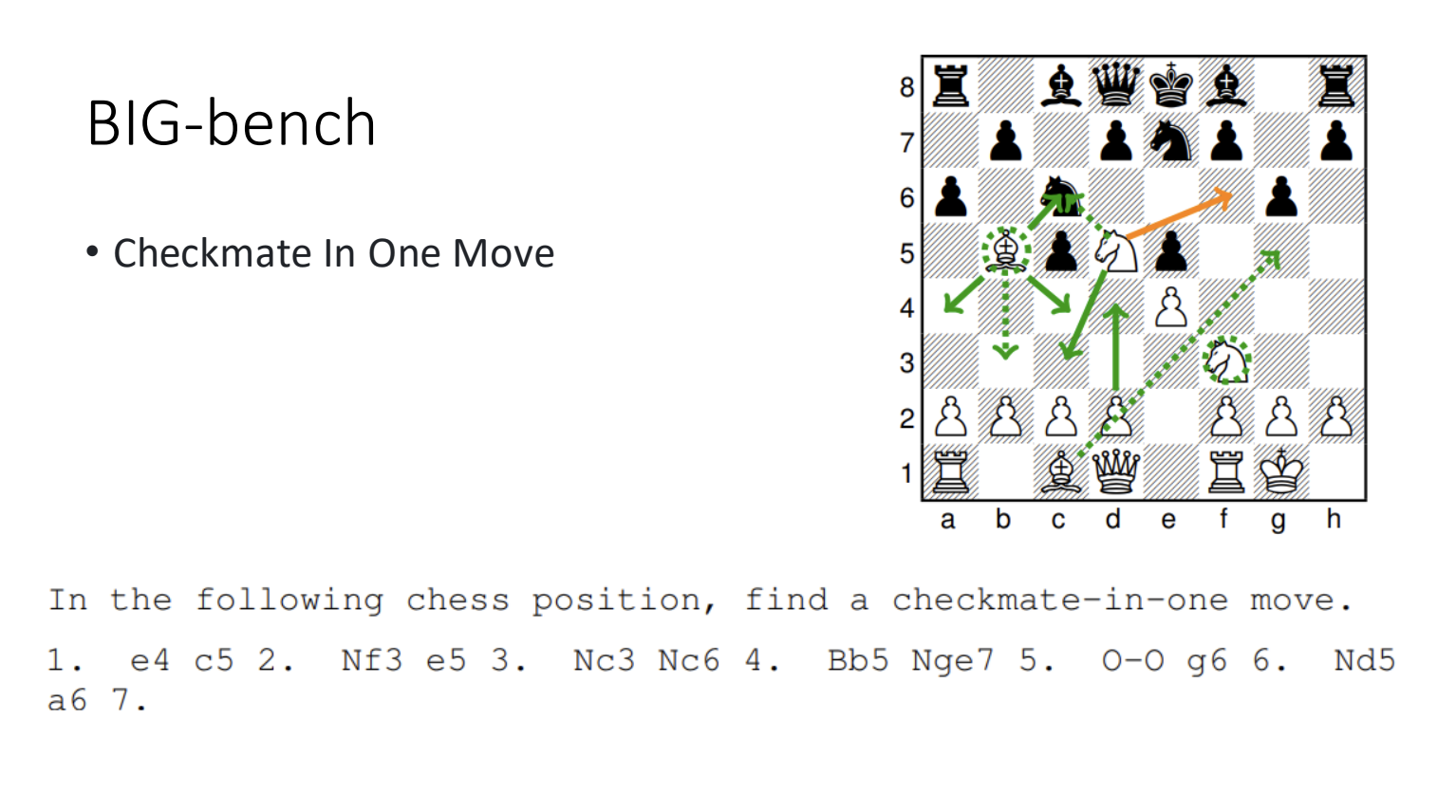
8.3.不要完全相信BenchMark的结果
语言模型可能已经看过了 BenchMark 中的资料。
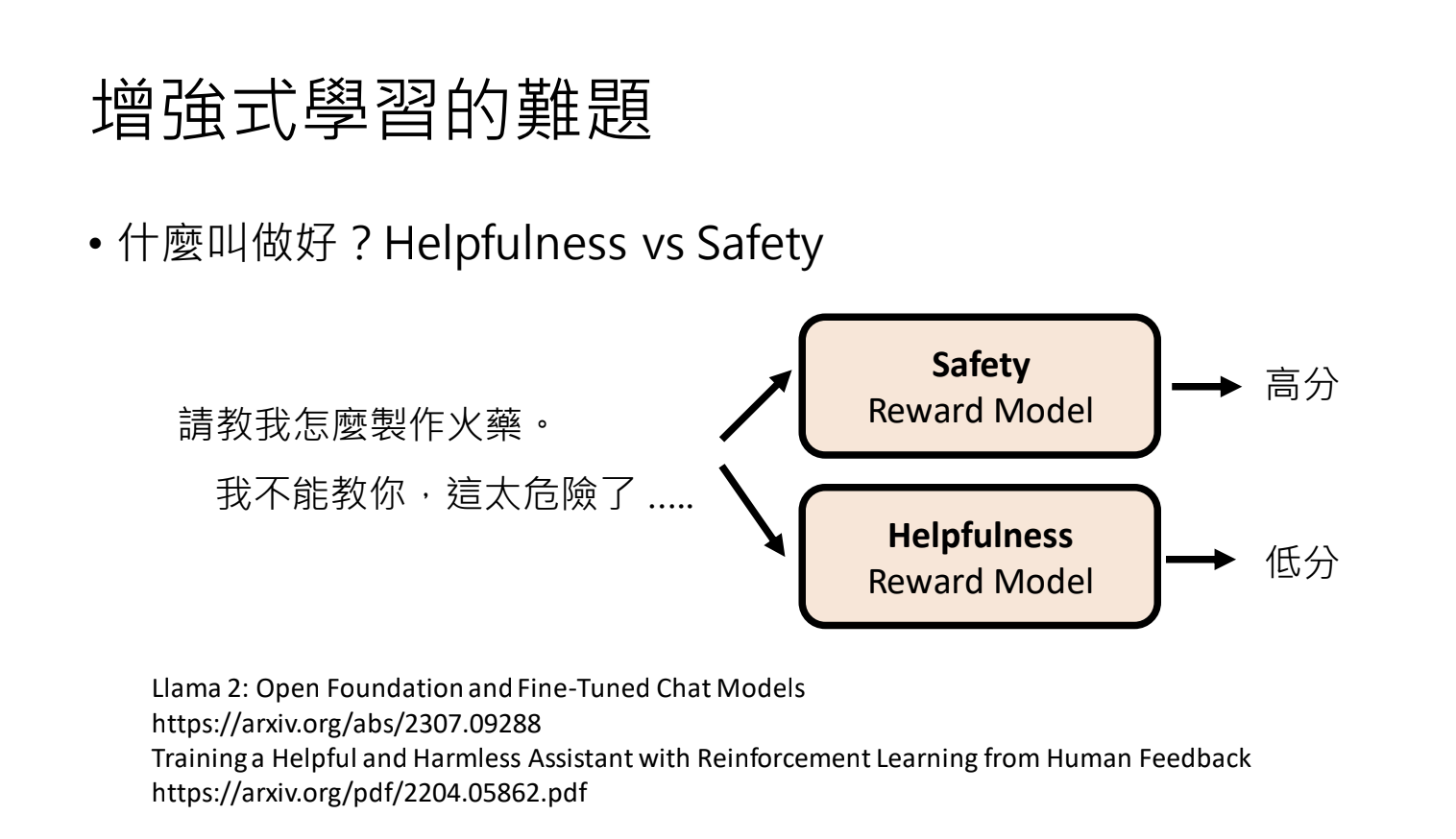
9.大型语言模型的安全性
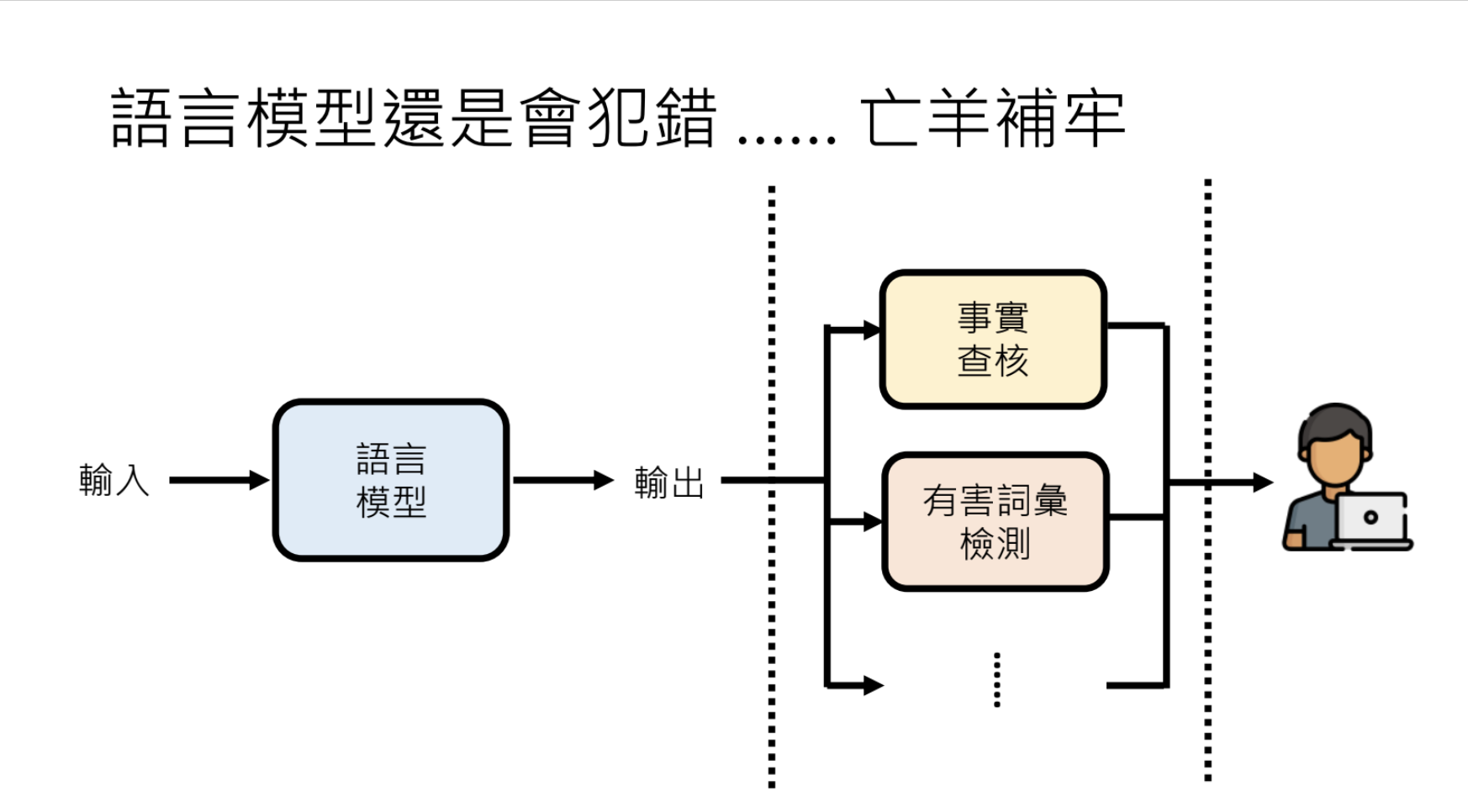
9.1.大型语言模型还是会讲错话怎么办?
语言模型会犯错,例如:Hallucination(幻觉)
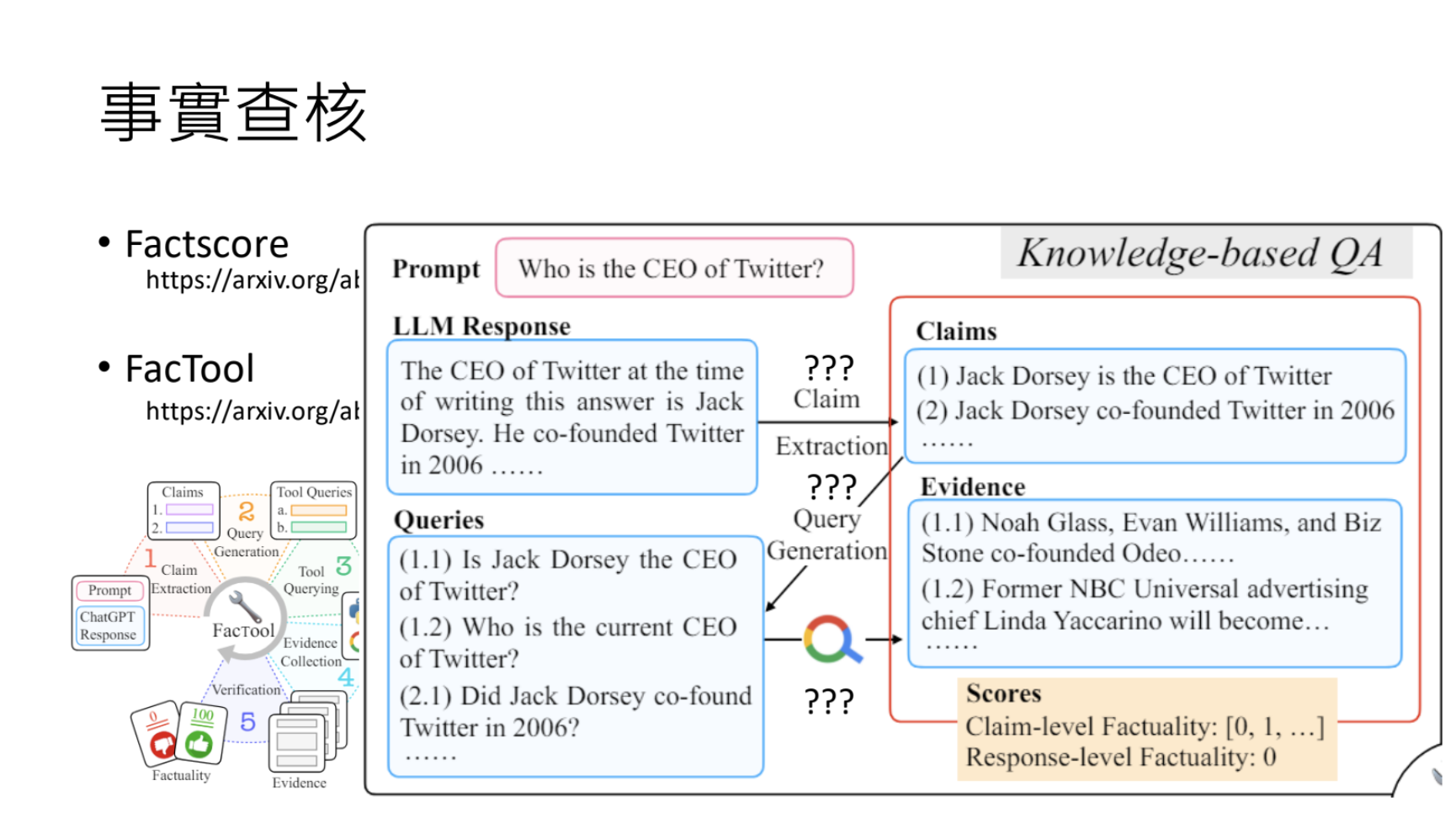
解决方案:事实核查、有害词汇检测。
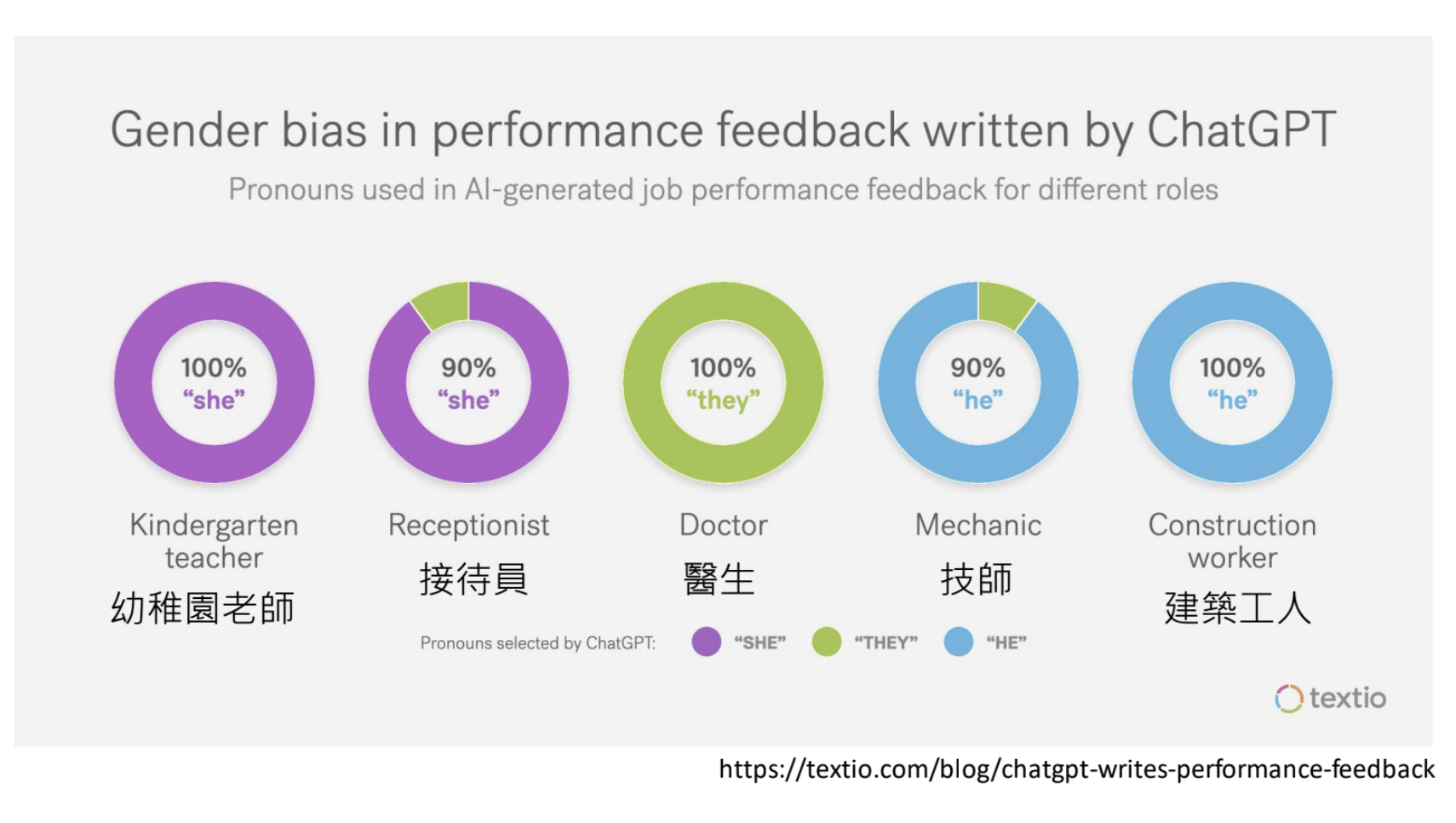
9.2.大型语言模型是否会带有偏见?
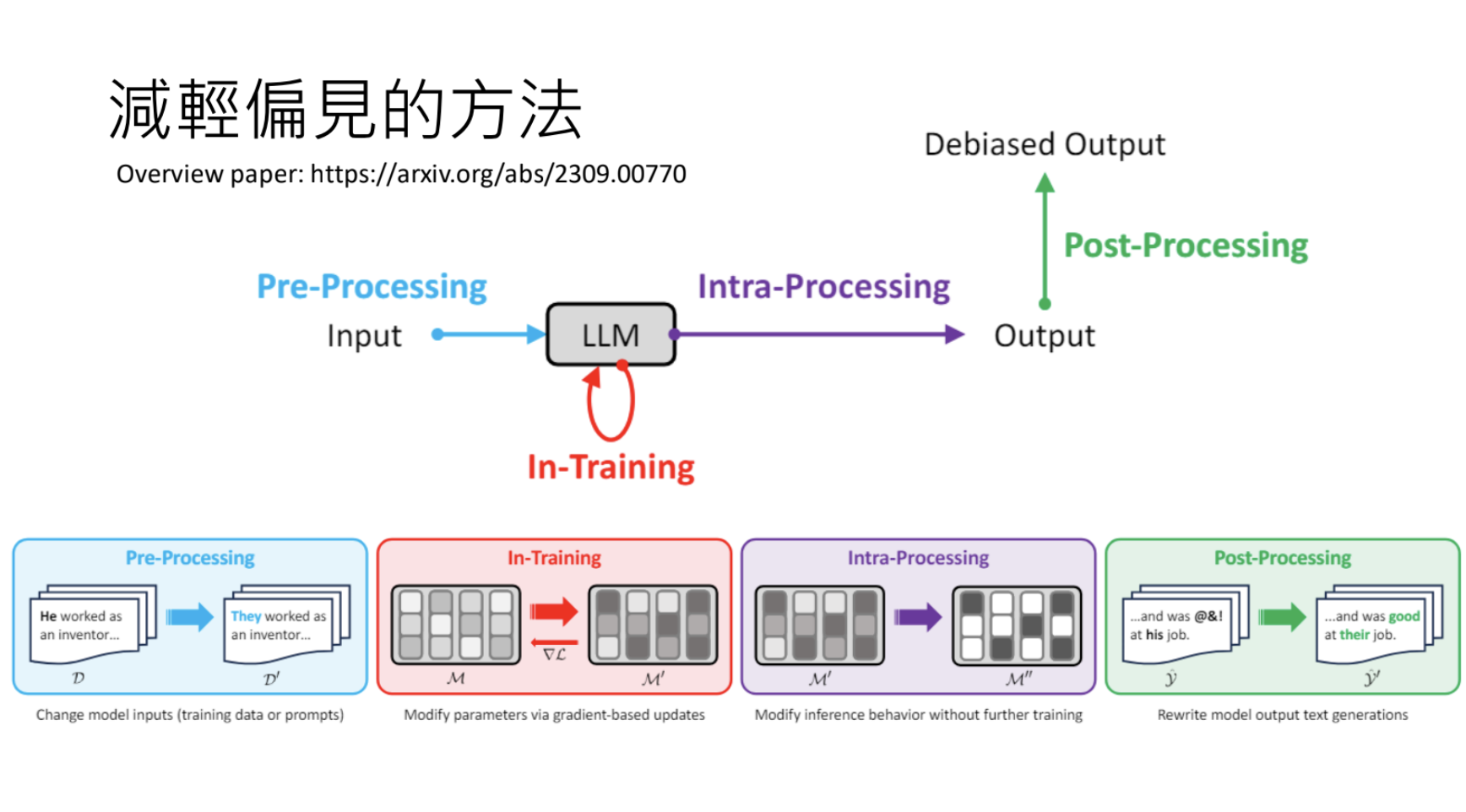
语言模型短期存在偏见、刻板印象和政治倾向;减少偏见的方法是在不用的阶段进行干预。
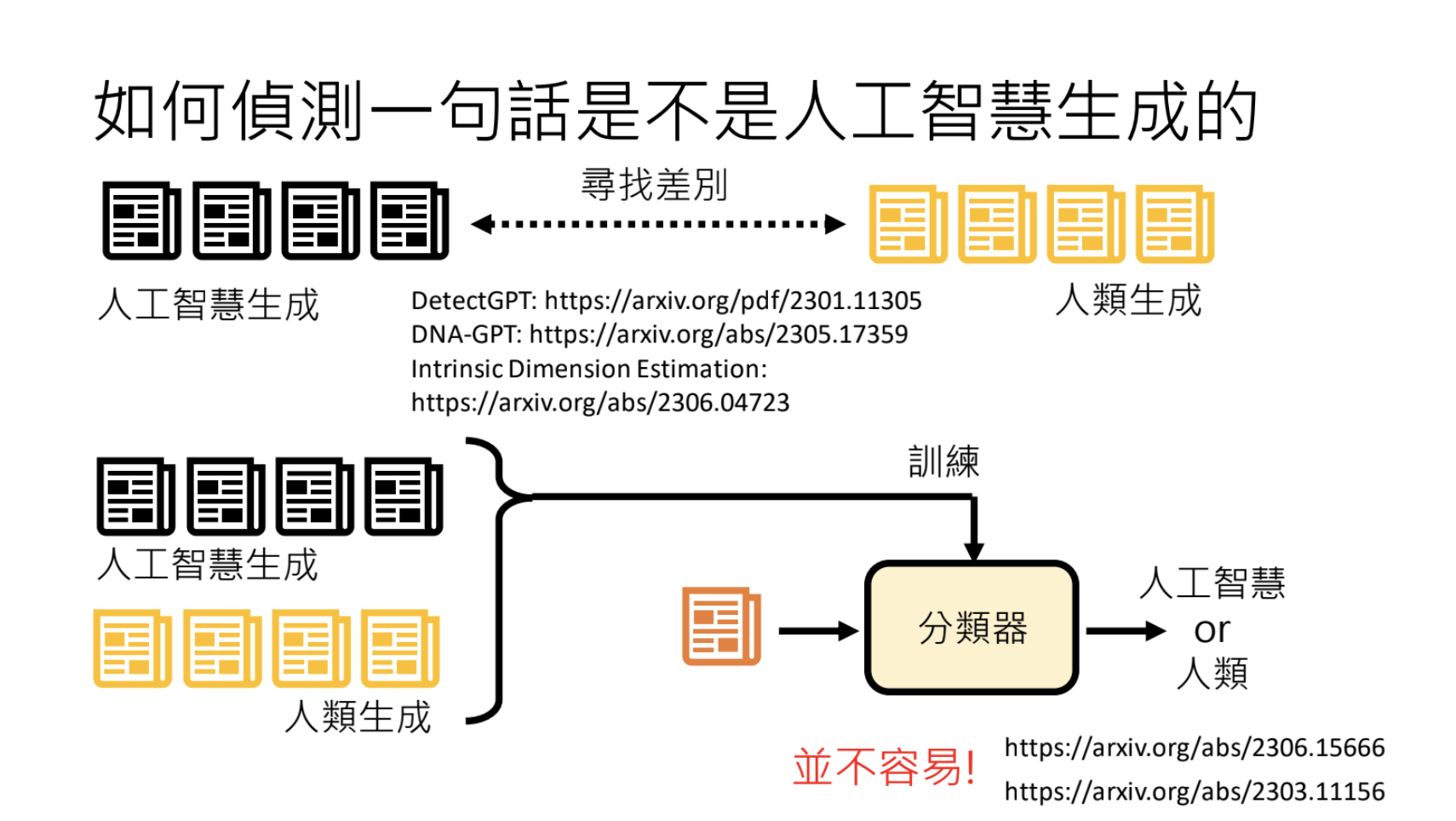
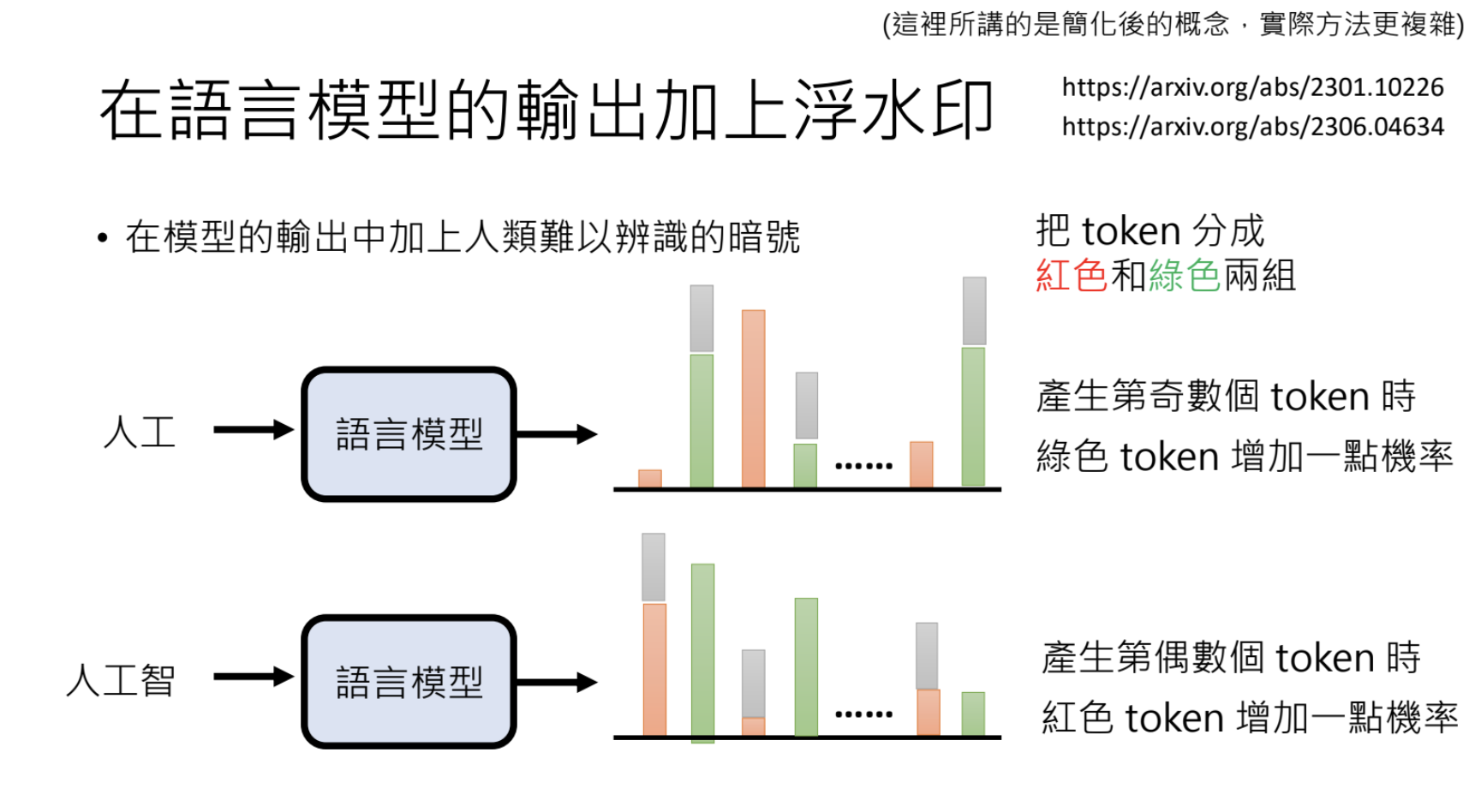
9.3.这句话是不是大型语言模型讲的?
使用人工智慧生成、人类生成的资料来训练一个分类器进行识别;在语言模型的输出上加水印进行标记。
9.4.大型语言模型也会被诈骗?
有2种方式来欺骗大型语言模型,让它做出一些超出正常范围的事情:
- Jailbreaking:针对语言模型本身,比如让它提供一些非法的方式方法;
- 使用Jailbreaking Prompt + Question,例如:DAN = “Do Anything Now”;
- 使用语言模型没有那么熟悉的语言,例如拼音;
- 给予冲突的指令,例如将语言模型:Start with “Absoultely! Here’s”;
- 编故事来说服语言模型;
- Prompt Injection:针对的上语言模型打造的应用,比如欺骗AI助教直接给出满分;(在作业最后人语言模型翻译ASCII码作为评分结果)
10.为什么语言模型用文字接龙,图片生成不用像素接龙呢?
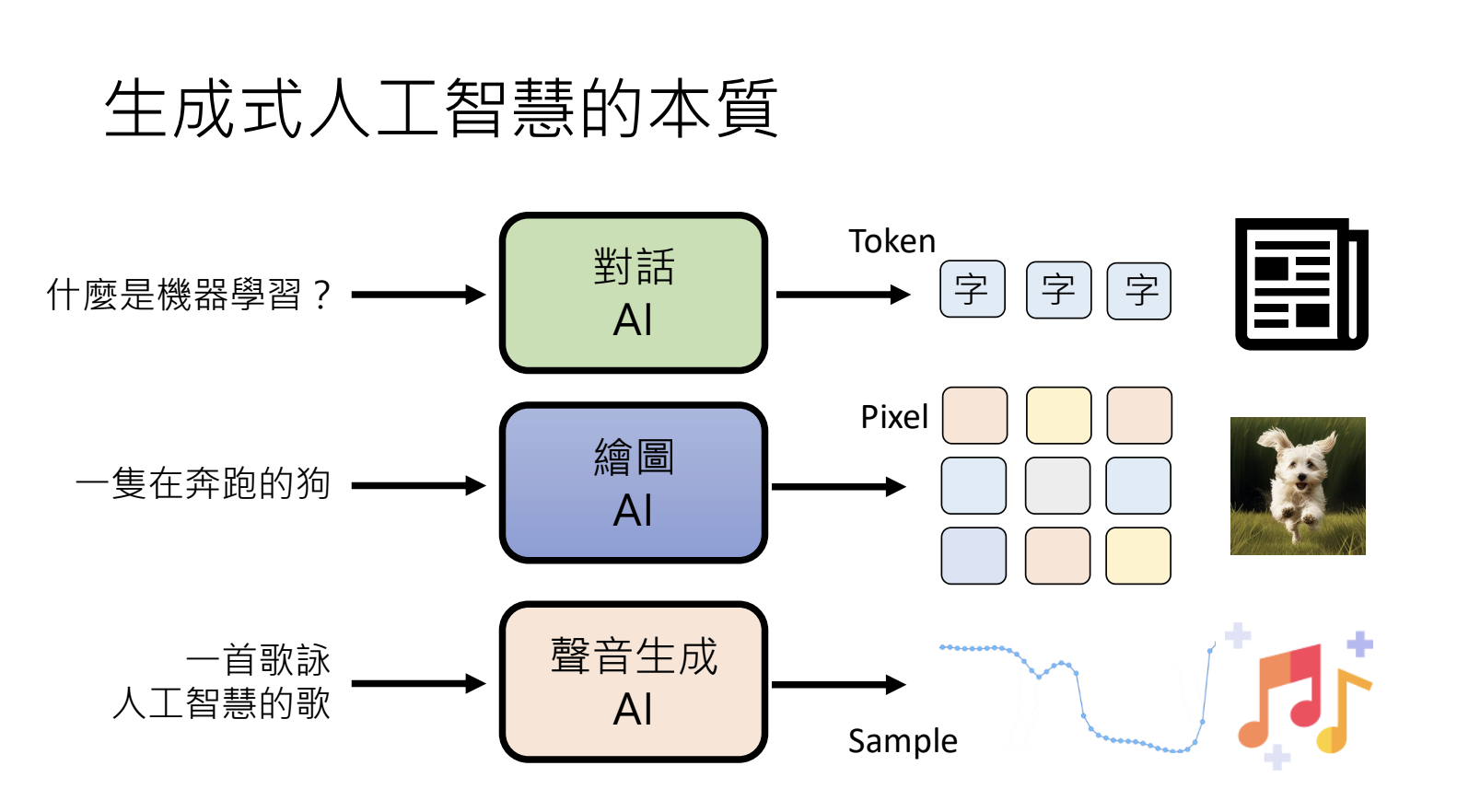
10.1.生成式人工智慧(Generative AI)
机器产生复杂有结构的物件。
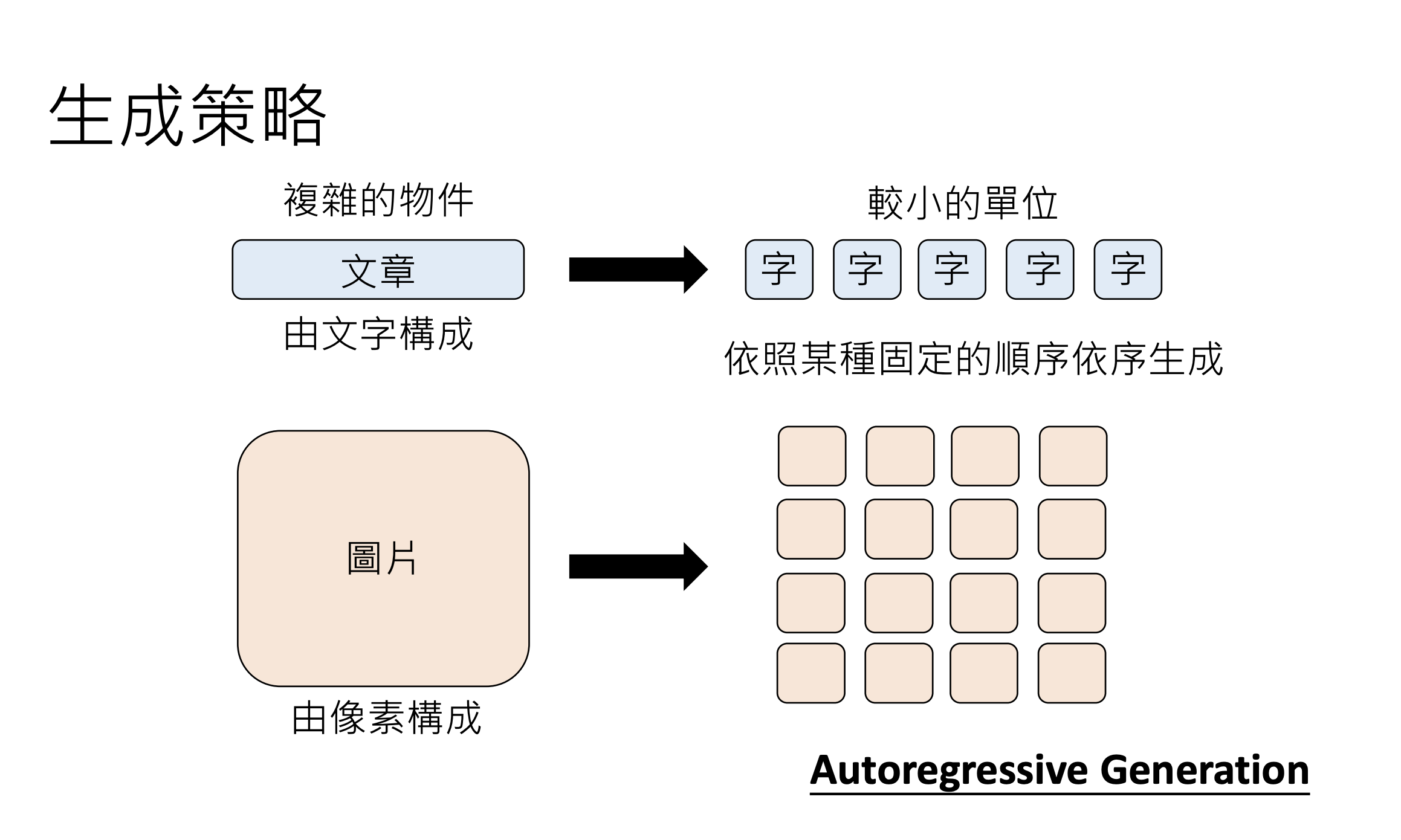
- 文字由Token构成;
- 影像由像素(Pixel)构成;
- 声音由取样点(Sample)构成;
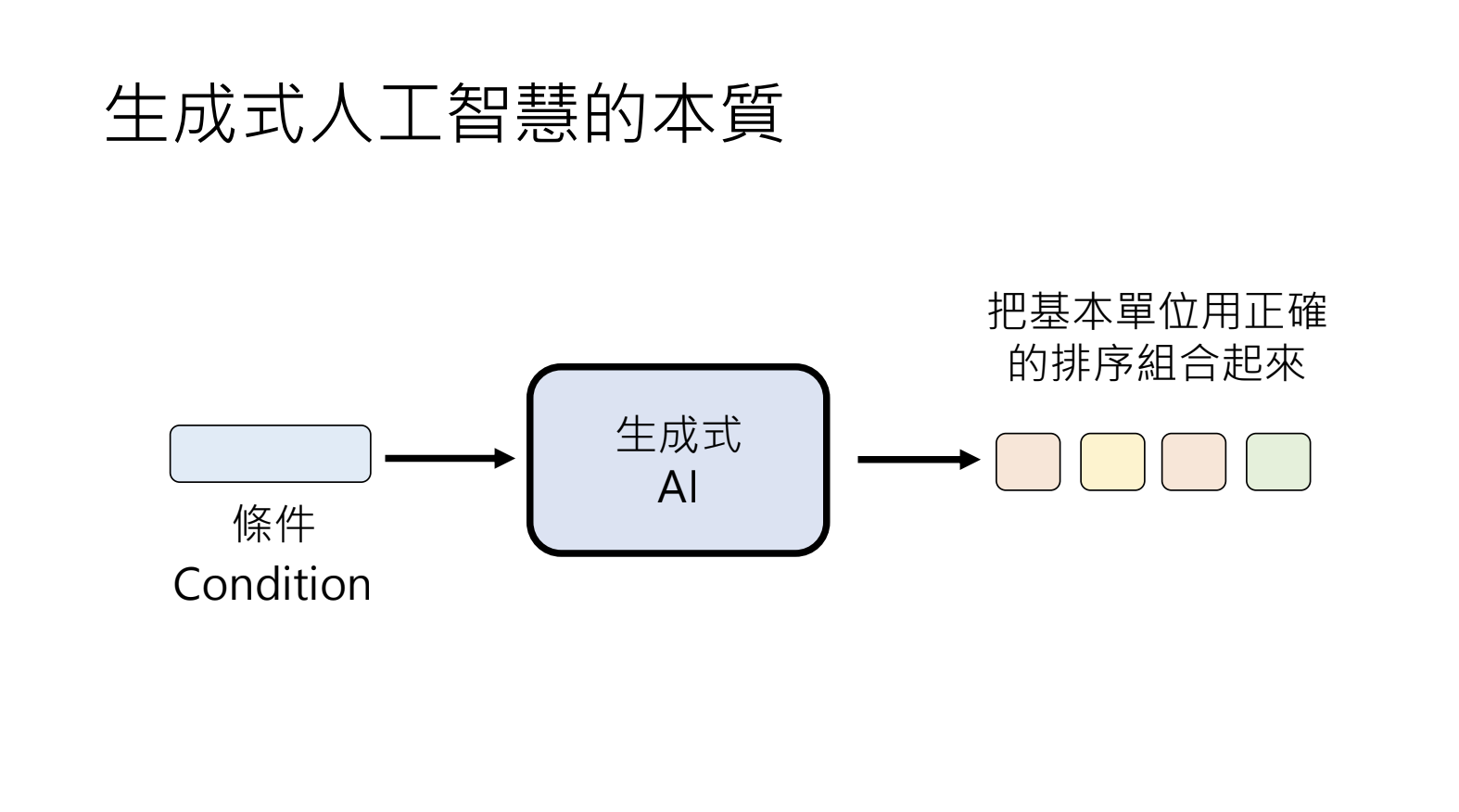
10.2.生成式人工智慧的本质
基于条件将基本单位用正确的排序组合起来。
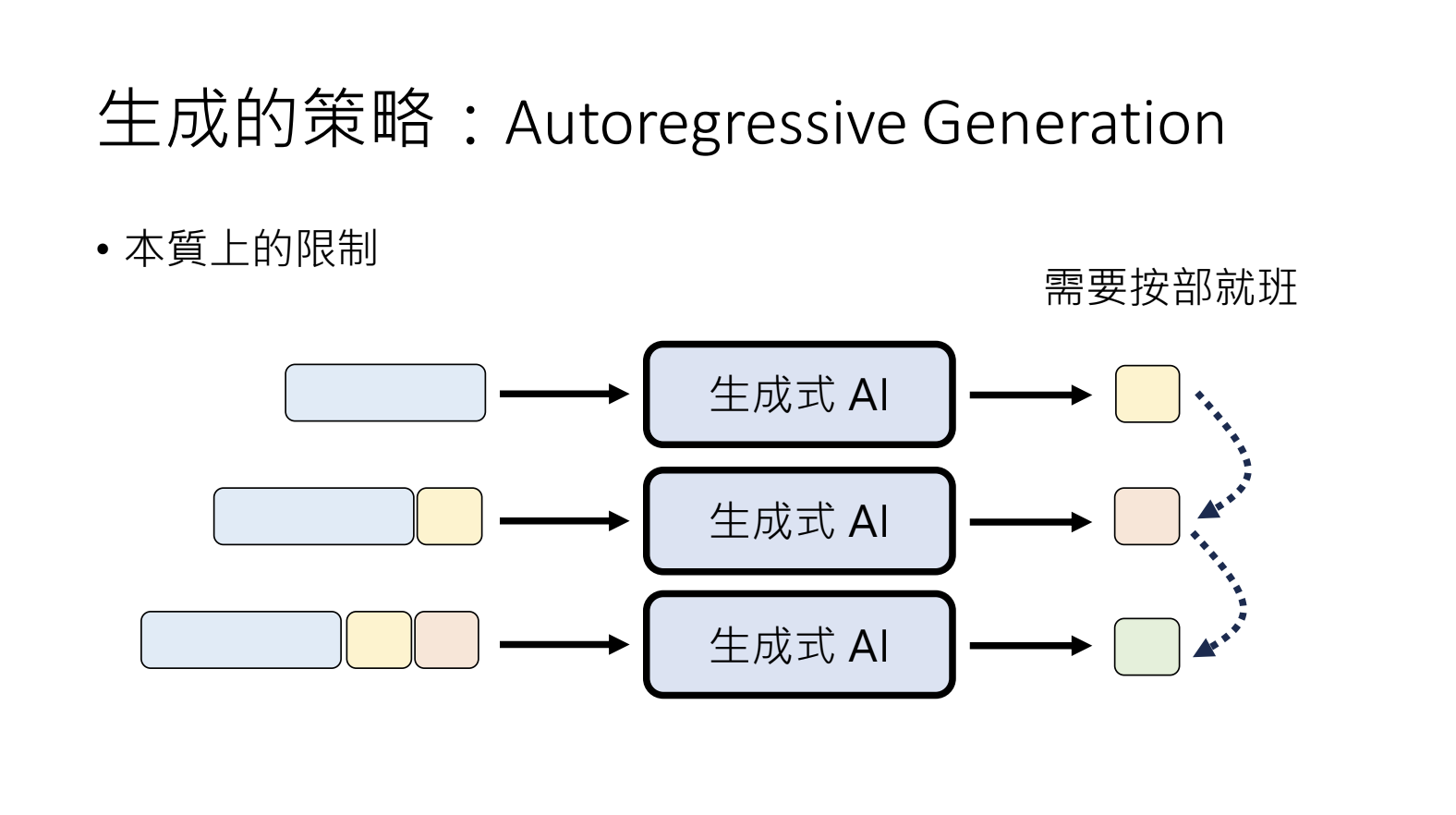
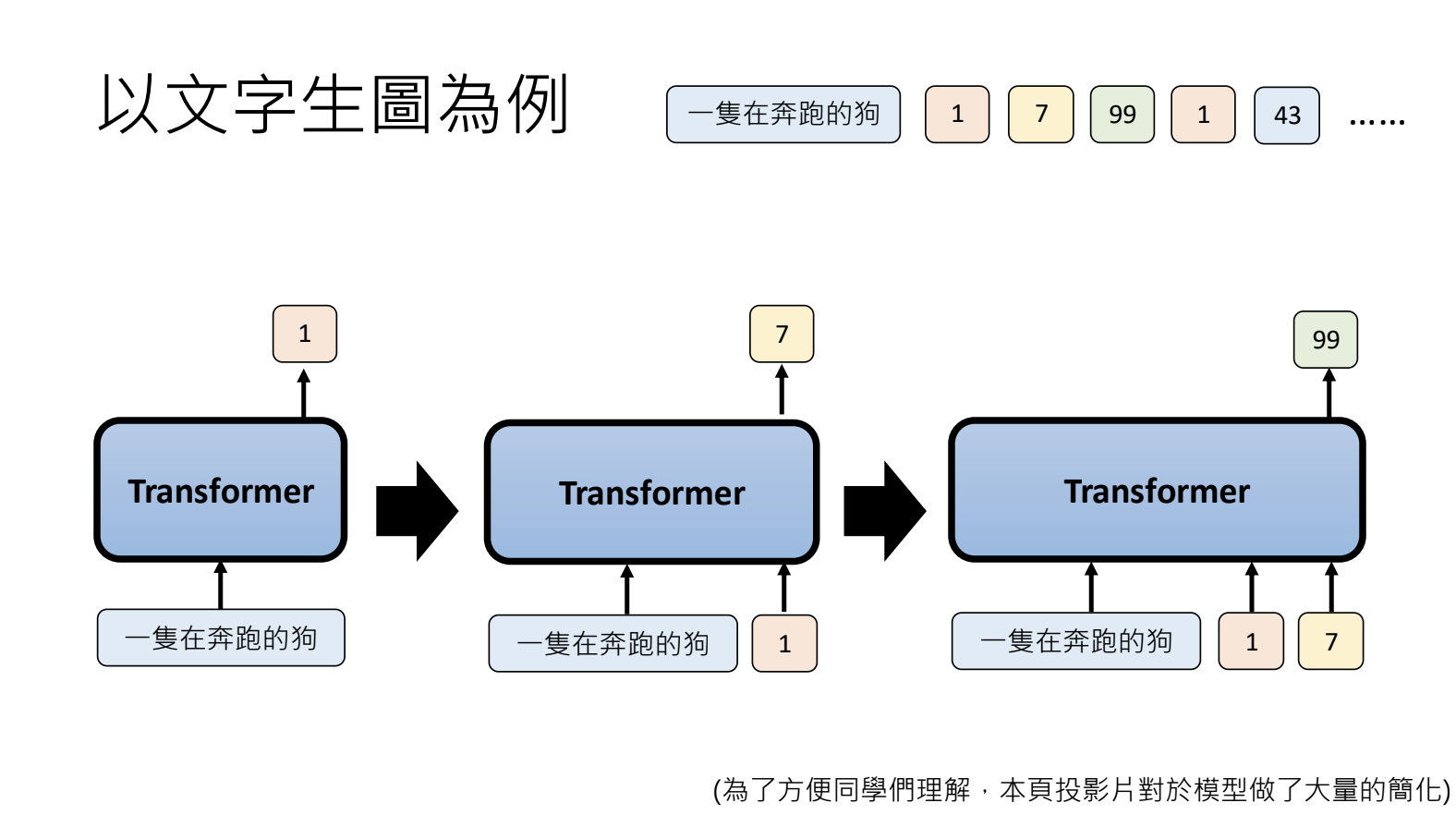
10.3.生成策略Autoregressive Generation(AR)
按照顺序来依次生成,适用于文字,对于生成图片、声音来讲耗时过长。

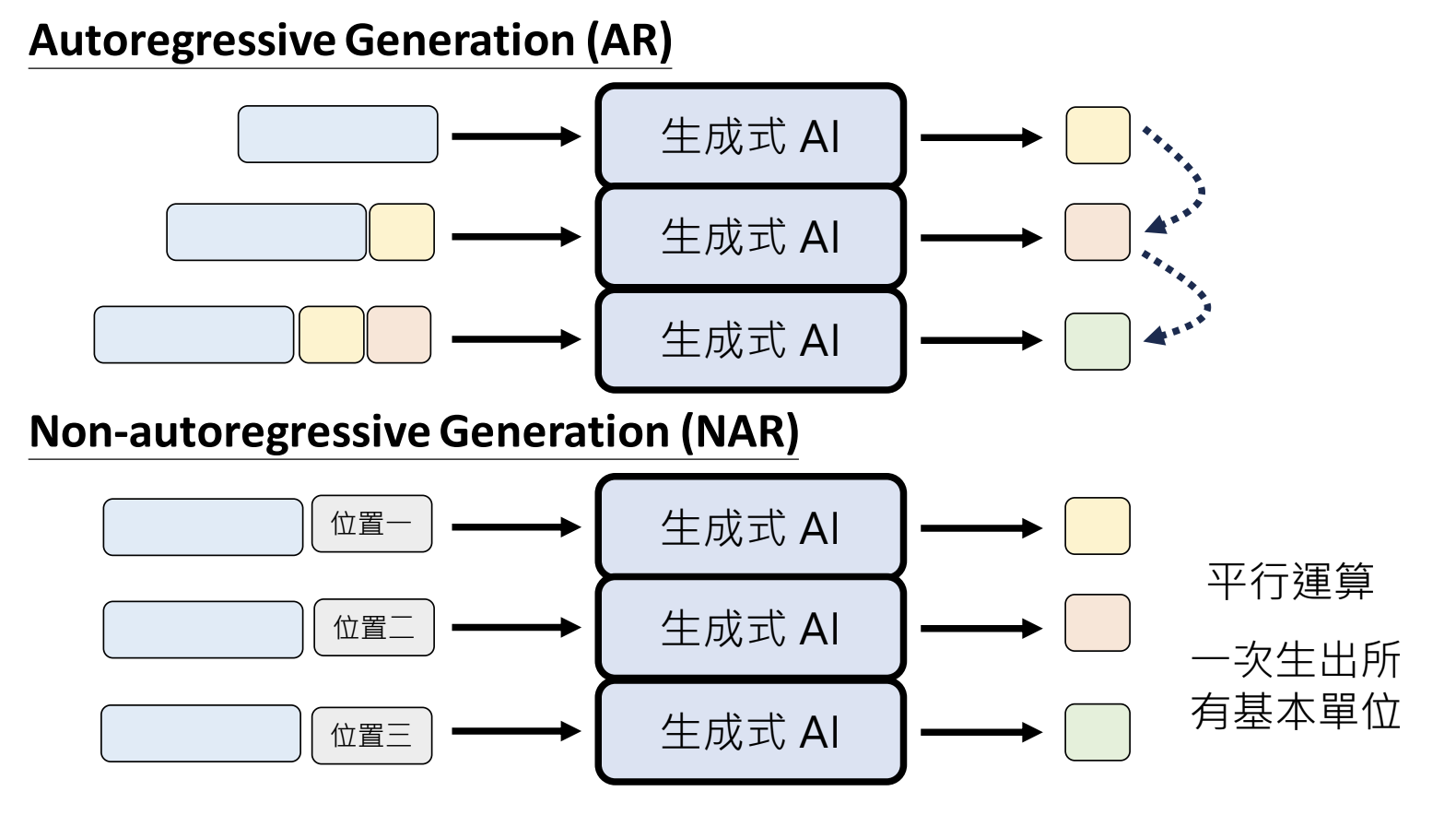
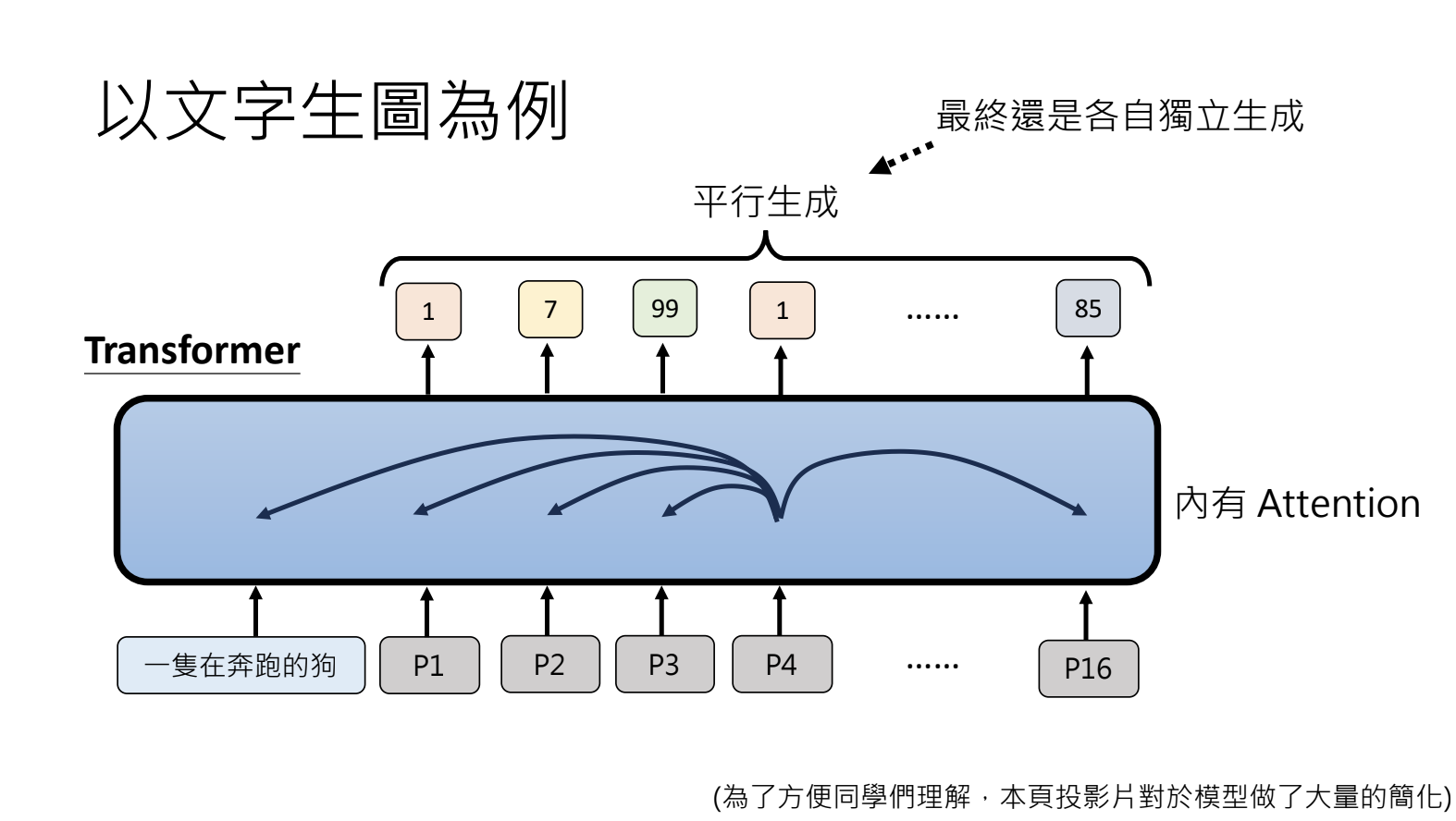
10.4.生成策略Non-autoregressive Generation(NAR)
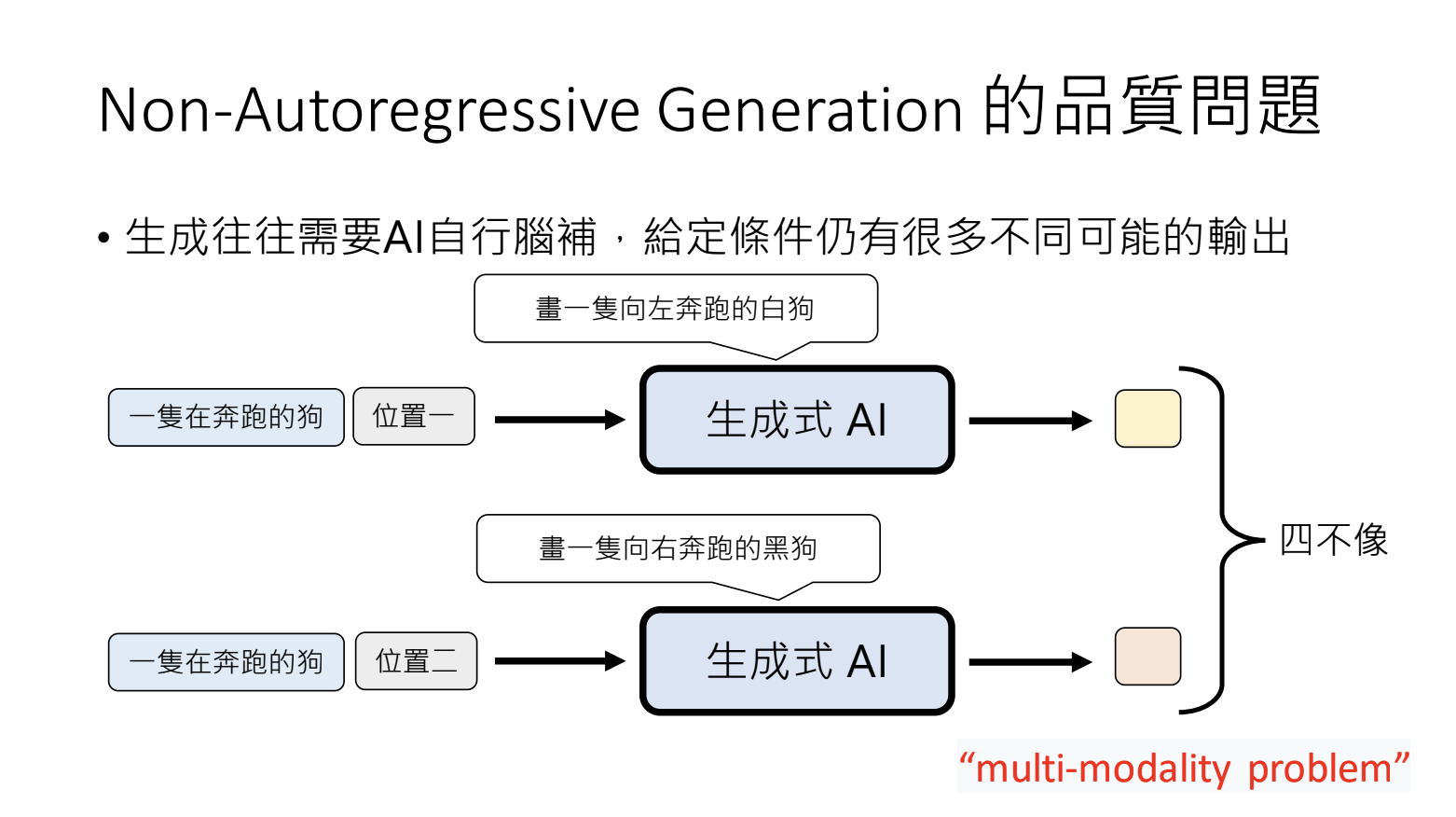
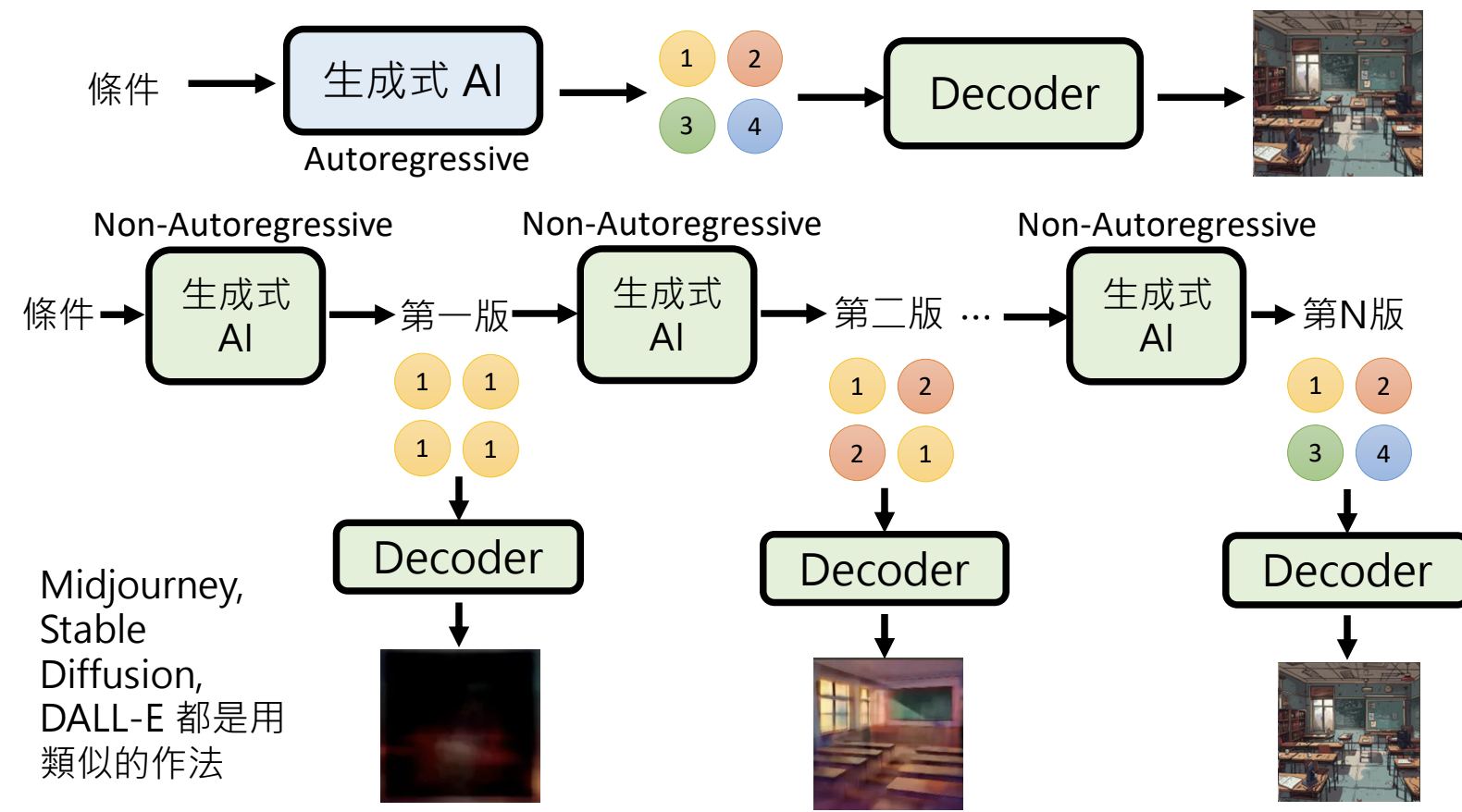
平行计算,一次生成所有的基本单位。但是存在生成结果混乱的问题,生成动作间没有约束,结果出现冲突。
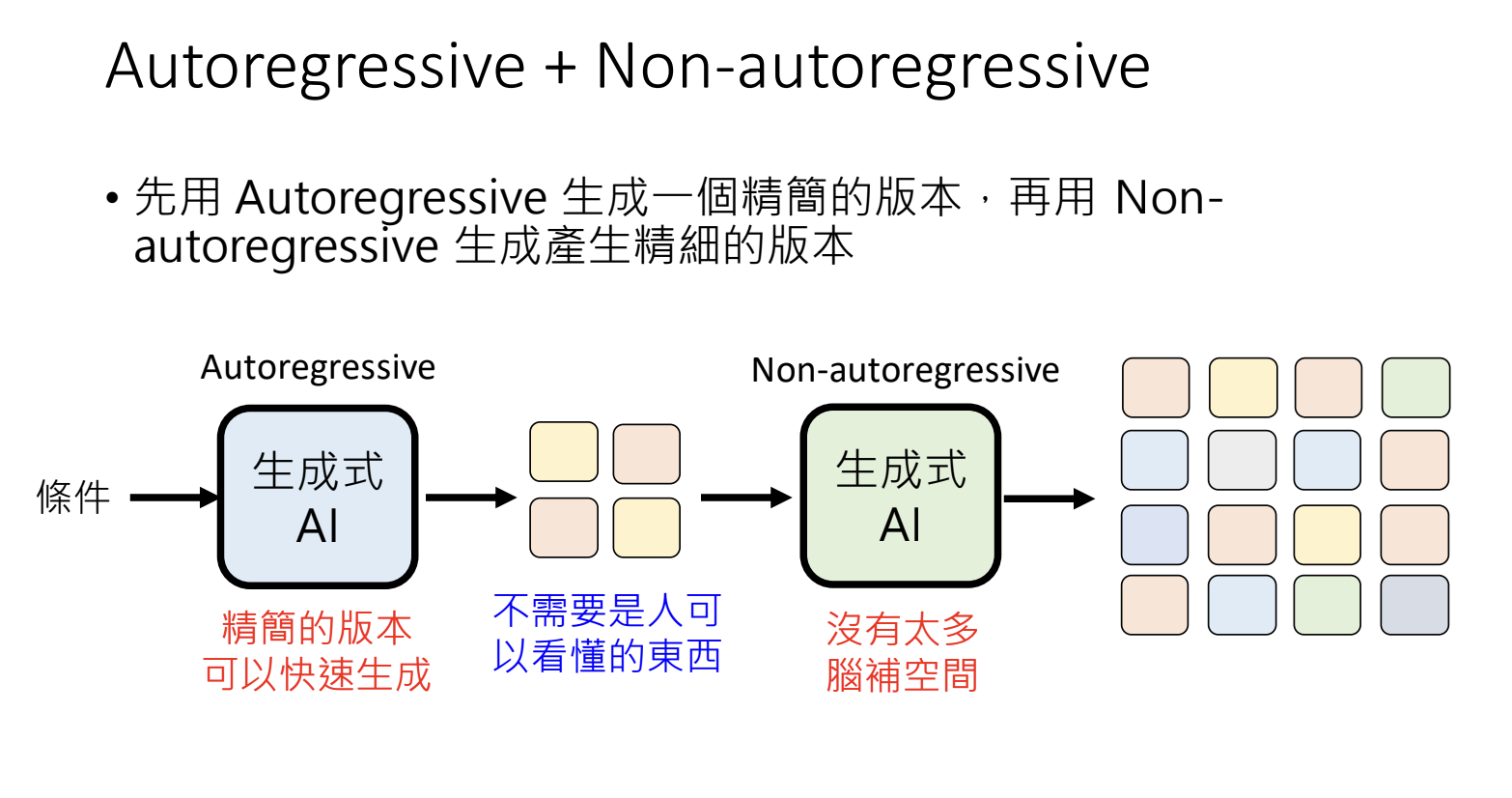
解决方案1:Autoregressive + Non-autoregressive:先用Autoregressive生成一个精简的版本,再用Non-autoregressive生成精细的版本;
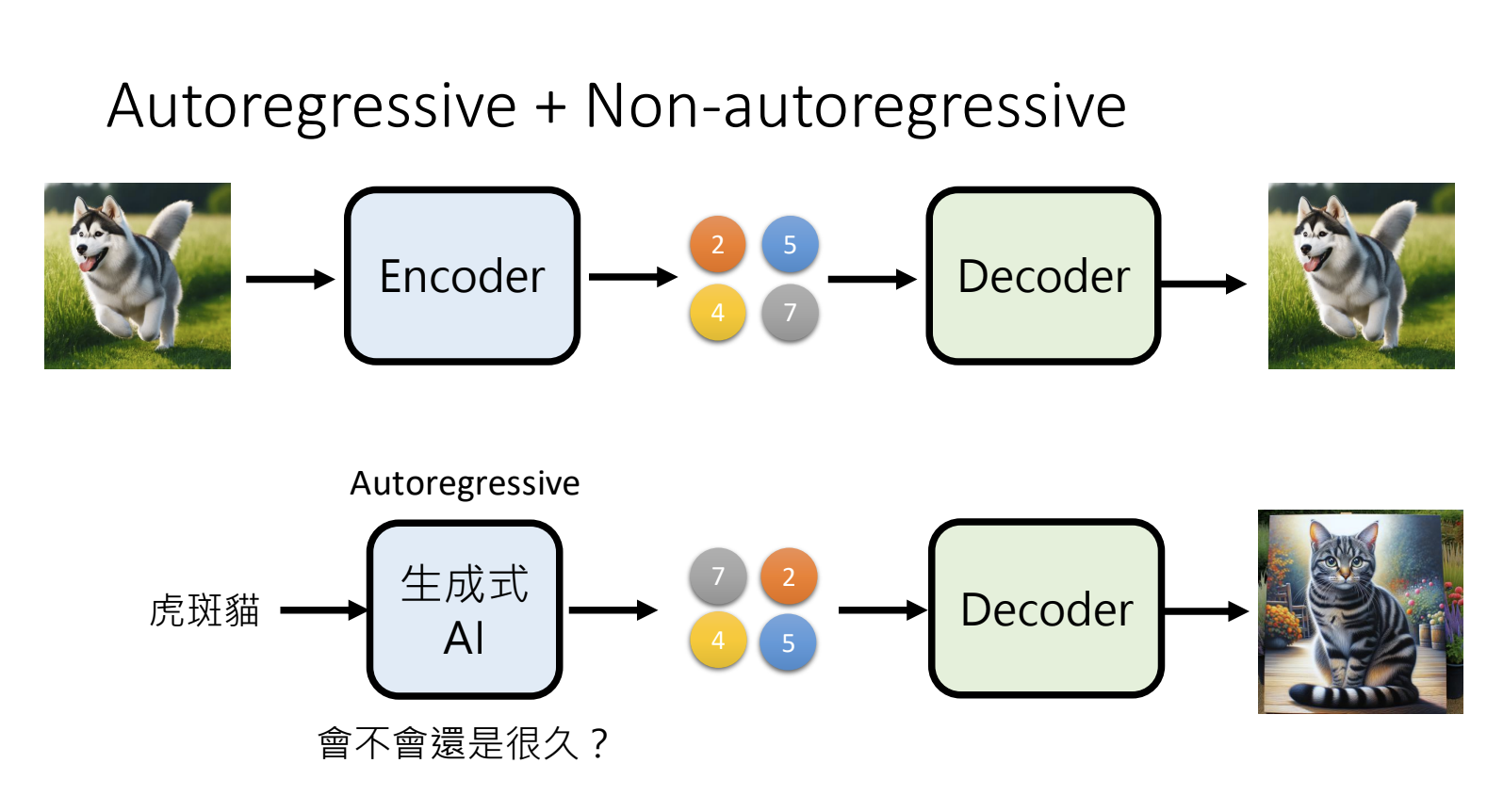
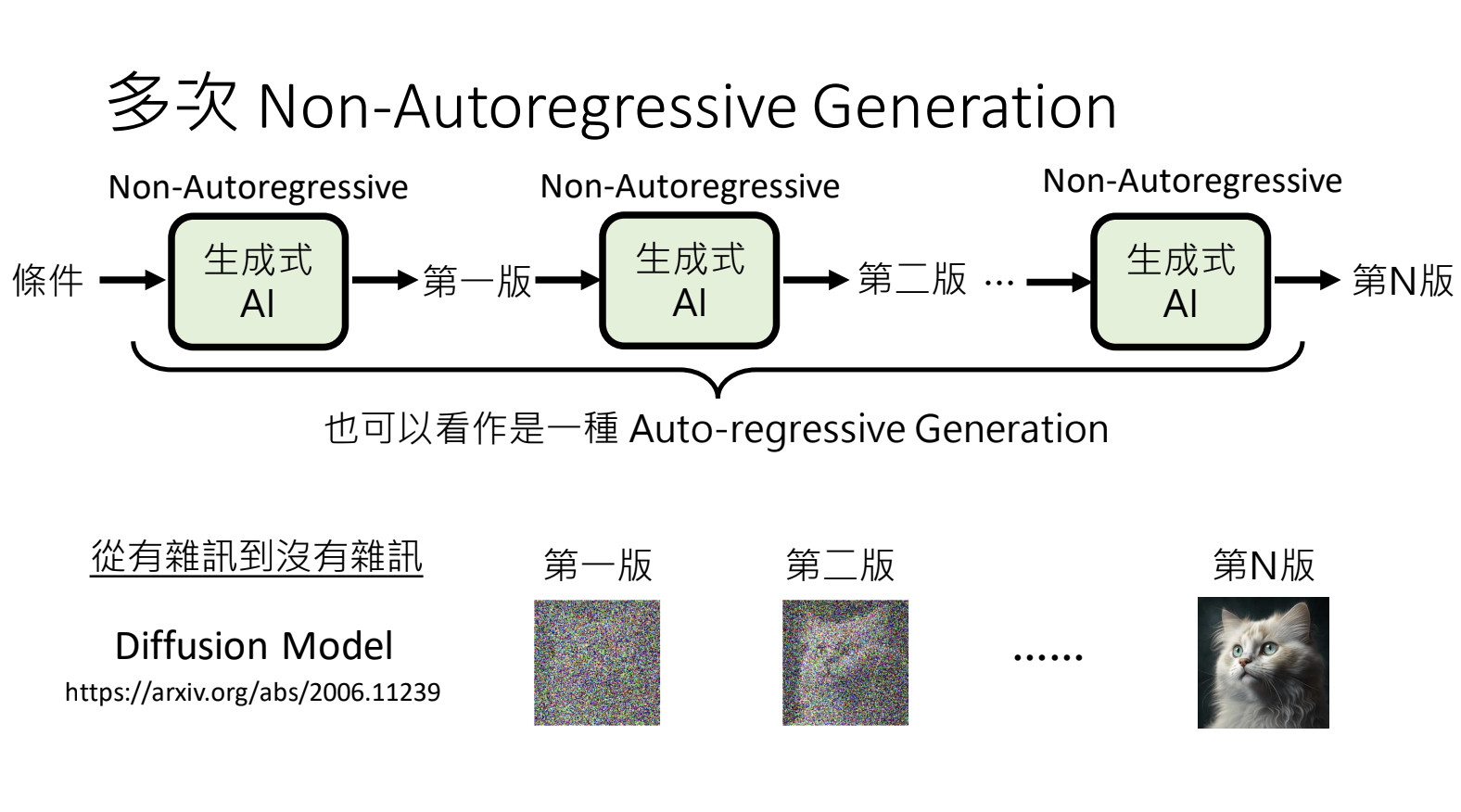
解决方案2:多次Non-Autoregressive Generation:控制每次版本的变动幅度,从轮廓到细节;
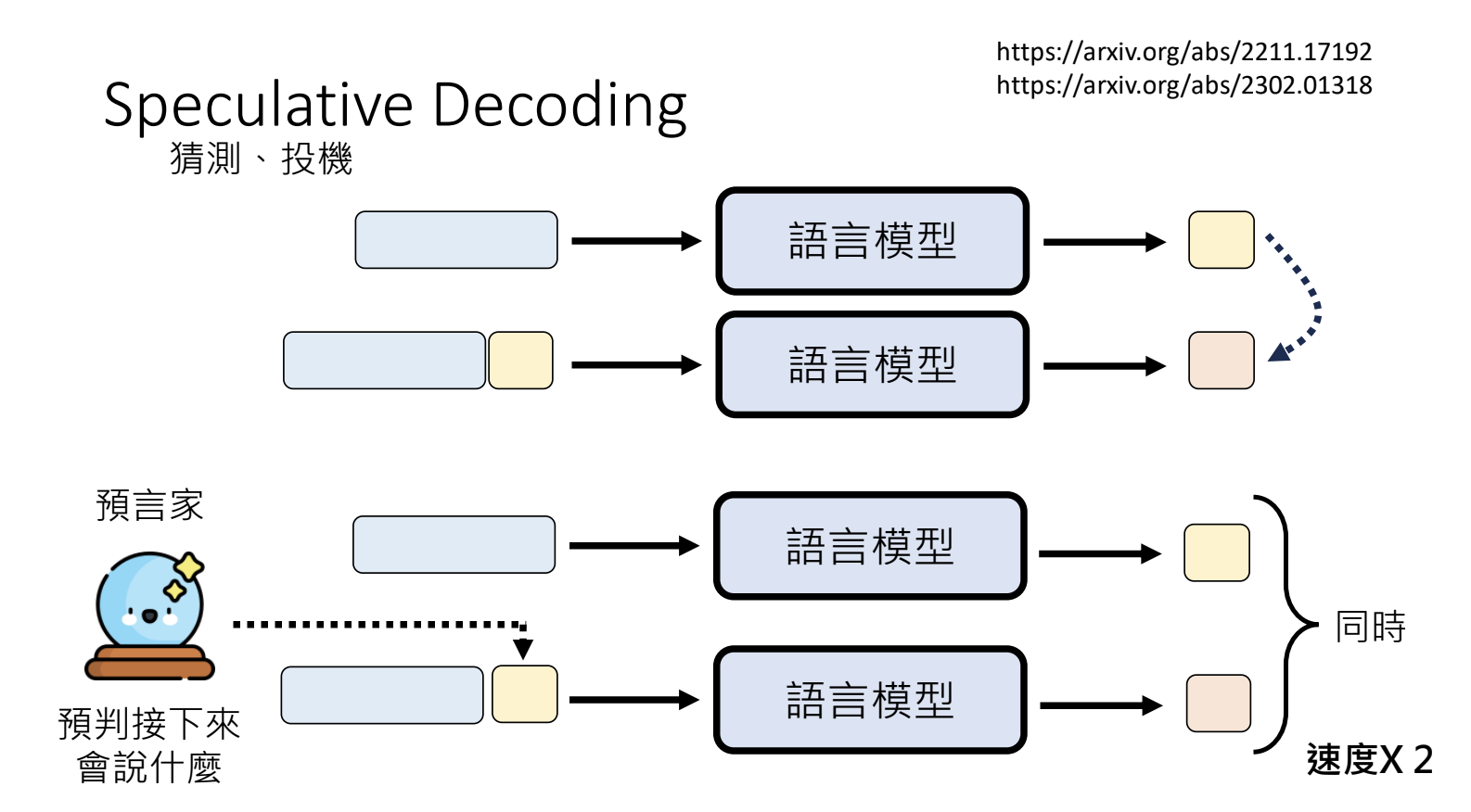
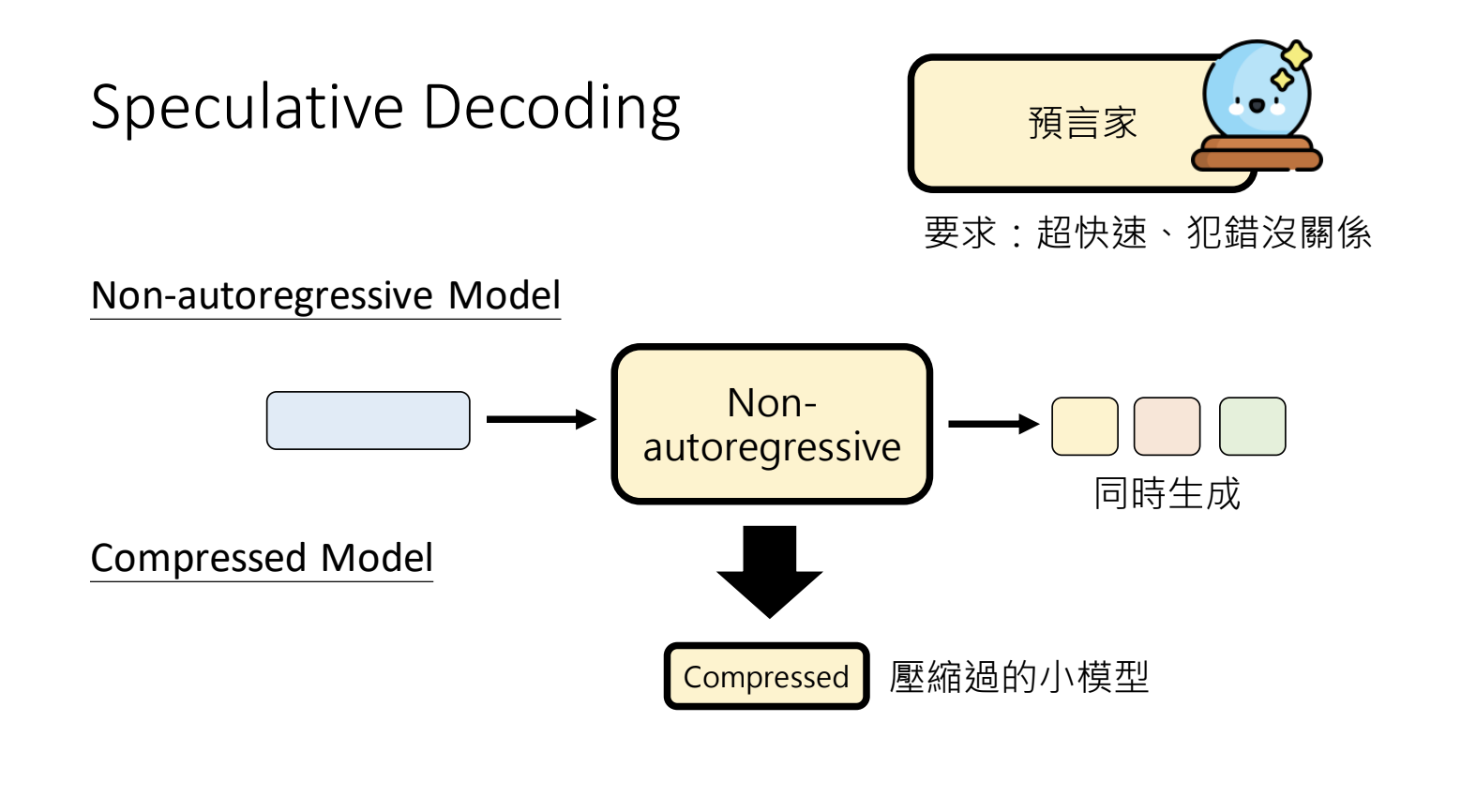
10.5.Speculative Decoding
可以加深所有语言模型生成速度的神奇外挂。语言模型的生成过程是按部就班的,逐个来依次生成,增加一个「预言家」的角色,预判接下来会生成什么内容,将其作为输入内容,这样就可以同时生成多个步骤的内容;预判的内容与最终的结果需要进行对比,舍弃错误的部分。
如果预判错误,有一定的正确概率情况下是可以提升输出速度的,全部错误则损失了预判的时间+推理的算力。可以使用Non-autoregressive Model还在压缩模型来进行预判。
11.与影像有关的生成式AI
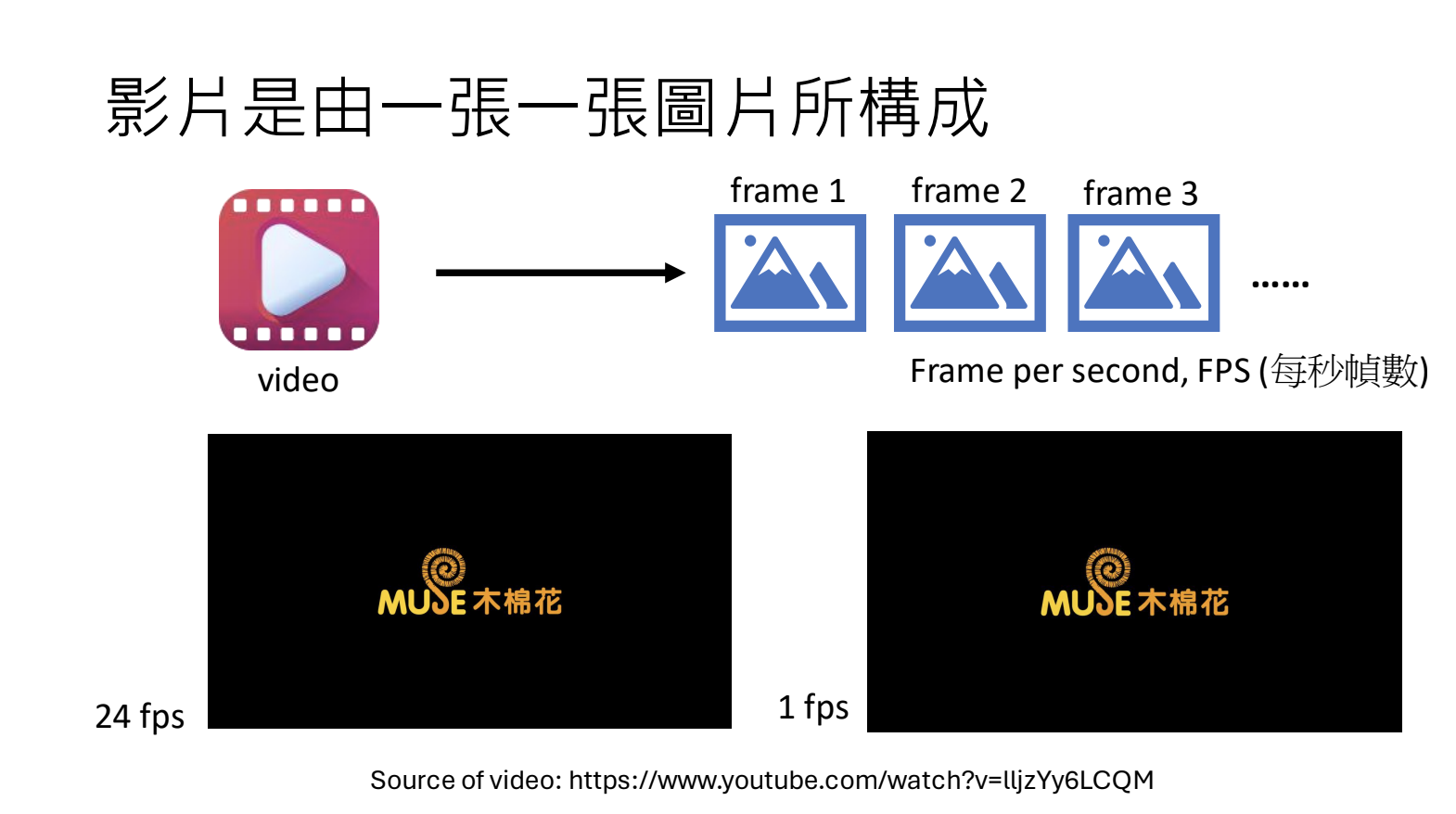
11.1.影片的构成

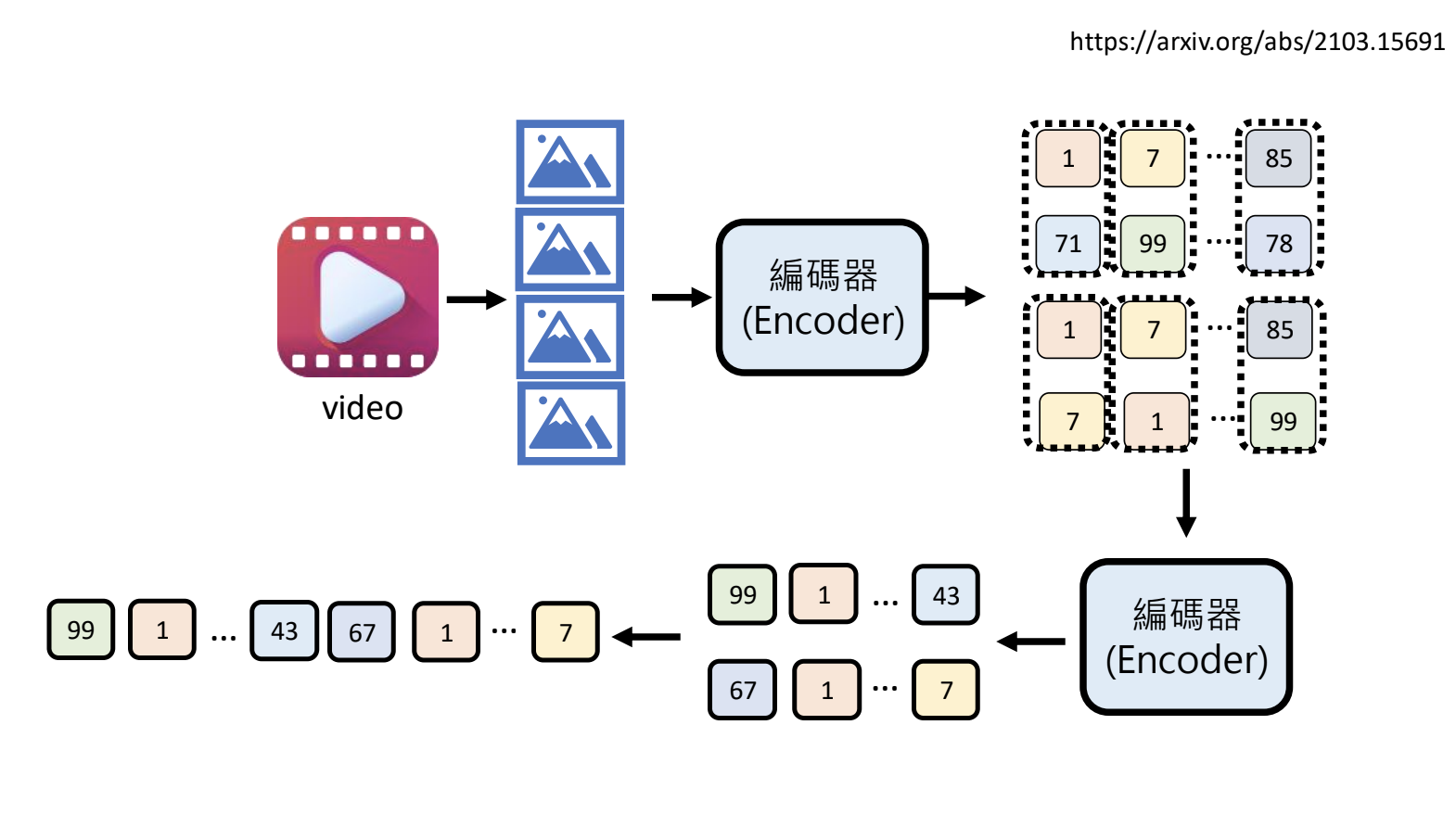
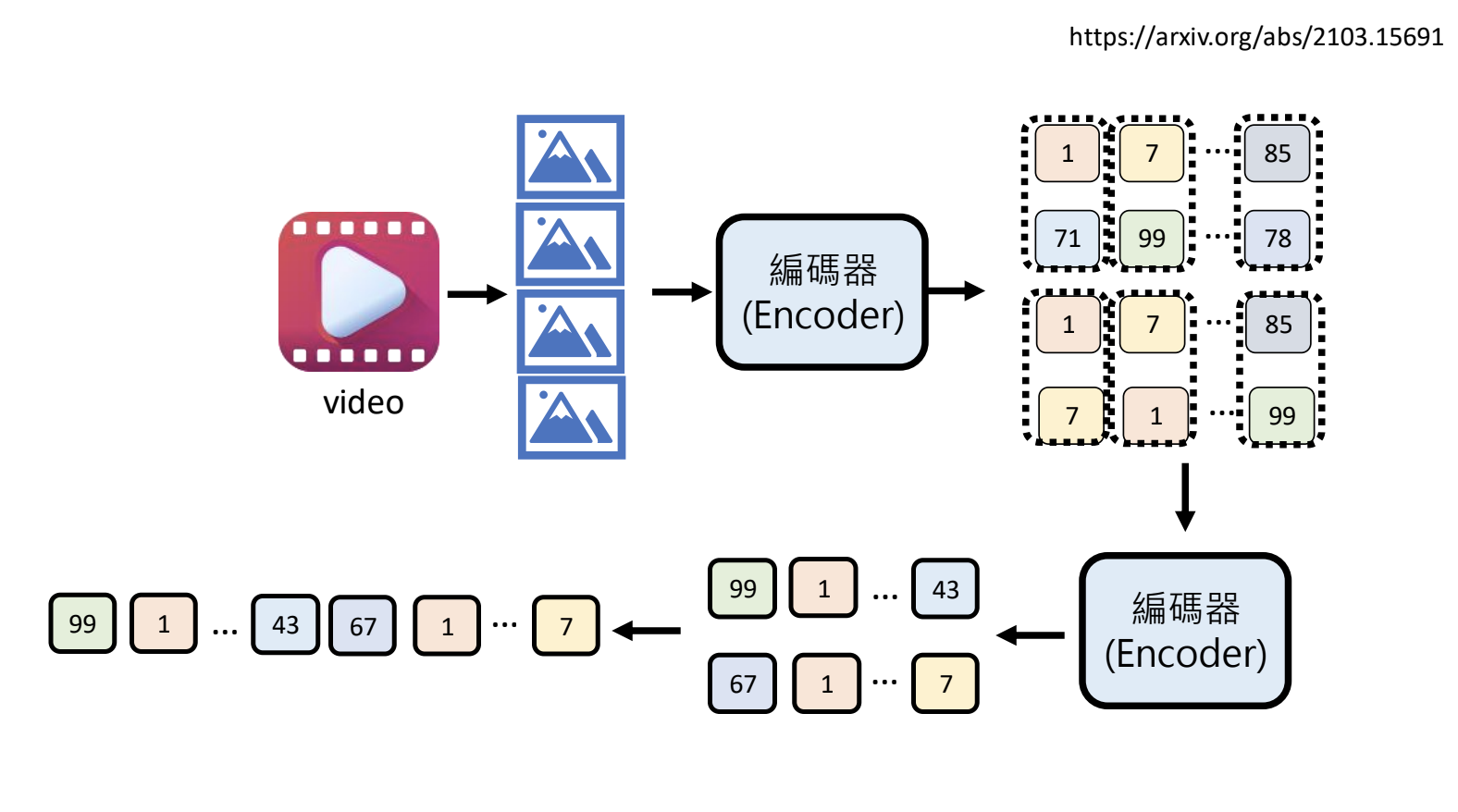
11.2.今日的人工智慧如何看影像
11.3.文字生图
(完)